I’m slowly starting to appreciate the role of metaprogramming in Objective-C and how to do it in a compiler-safe manner. With dynamic methods, there are are two cases: you can either send a message that the receiver doesn’t necessarily know about at compile-time, or you can receive a message that the sender might know about at compile time.
Dynamic Method Resolution
Receiving a message that you didn’t publicize at compile-time is called dynamic method resolution. Rails uses this to great effect with dynamic finders. They let you call User.find_by_email('soroush@khanlou.com'). That message will be caught at run-time in the User class and dynamically return the result of User.find_by('email', 'soroush@khanlou.com'). This would automatically work for every property you have on your model object. Strictly speaking, this is possible in Objective-C (I show how exactly in an article about dynamic Objective-C on the Rap Genius tech blog). However, there are a number of things in Objective-C that prevent us from writing code like this, including
ARC, which requires the method signature of every method to be known at compile-time, so that clang can insert retains and releases at the right time
compiler warnings, which assure that the methods we are calling are actually publicized (in a header) and that the methods that we publicize actually exist
Dynamic Message Construction
On the other hand, you can have a method that the sender builds at run-time but the receiver has already defined at compile-time. This is called dynamic message construction, and, crucially, the compiler won’t stand in our way for this technique.
You can see dynamic message construction at play in Core Data’s validators. Core Data will dynamically check for and call methods of the form validate:error:. For example, if you had a “name” property, Core Data would dynamically call -(BOOL)validateName:(id *)ioValue error:(NSError **)outError, giving you the power to validate it, return an error describing why it’s not valid, or even change the pointer to the object its asking you to validate. This could all be rolled up into one big method called -validateValue:forKey:withError:, but that could grow to be a pretty big method! You’d probably want to separate each of the validations like so:
- (void)validateValue:(id *)value forKey:(NSString *)key withError:(NSError *)error {
if ([key isEqualToString:@"name"]) {
[self validateName:value error:outError]
}
if ([key isEqualToString:@"email"]) {
[self validateEmail:value error:outError]
}
}
A new refactoring
To that end, I present a new refactoring strategy: Replace Conditional With Message Construction.
Martin Fowler’s book, Refactoring, in addition to outlining the intention behind refactoring and the methodology for doing it safely, also includes a catalog of refactoring strategies (including Replace Conditional With Polymorphism, which is what inspired this blog post).
Core Data shows us how this is used in the model layer, but let’s look at an example in the view layer as well.
In the Rap Genius app, we use -configureCell:atIndexPath: when setting up cells to separate the creation of the cell from its configuration. If a table view has many types of objects represented in its rows, we want to break down our configuration method even further:
- (void)configureCell:(UITableViewCell *)cell atIndexPath:(NSIndexPath *)indexPath {
id object = [dataSource objectAtIndexPath:indexPath];
if ([object isKindOfClass:[RGArtist class]]) {
[self configureCell:cell withArtist:object];
} else if ([object isKindOfClass:[RGSong class]]) {
[self configureCell:cell withSong:object];
}
}
As this gets more and more complex, it is a ripe place to use this refactoring.
- (void)configureCell:(UITableViewCell *)cell atIndexPath:(NSIndexPath *)indexPath {
id object = [dataSource objectAtIndexPath:indexPath];
SEL configurationSelector = [inflector selectorWithPrefix:@"configureCell:with" propertyName:[[object class] modelName] suffix:@":"];
if ([self respondsToSelector:configurationSelector]) {
[self performSelector:configurationSelector withObject:cell withObject:object];
} else {
[self configureCell:cell withObject:object];
}
}
This code will now dynamically get the modelName of your model (such as “Song”), and call configureCell:withSong: or configureCell:withArtist: as appropriate.
The great thing about this pattern is that it helps separate your code into very logical units without having to include a giant conditional that is brittle and prone to change. It truly shines in a framework, where you may not know what objects are going to be represented in your table view, and it becomes crucial to call their configuration methods dynamically.
Graham Lee has been writing a series of posts about Model View Controller and its meanings, with historical and contemporary contexts. His most recent post, Inside-Out Apps, is a good read.
The question is simple: What do we mean when we say MVC? The M and V, of course, are obvious. The Model represents your data and the actions you want to perform on it. The View displays that data. What’s in between is nebulous.
In iOS, Controllers are View Controllers, with the prefix UI, suggesting that they’re very tightly coupled with the View layer. In Rails world, Controllers receive an “action” from the router and fetch and prepare data for the View, which is more of a template. In Java, Controllers explicitly observe their Models, updating their Views anytime something happens.
These are all very different ways of considering the C in MVC. They probably should all have different names. In fact, they do all have different names. And pretty pictures.
A quick note: My blog post is the first result for a Google search for “model view whatever”, which is a common catchphrase in the AngularJS world. The Angular team wants you to use “whatever” of the following systems work for you. Here is a link with more information from a member of the Angular team. Without further ado, here are the different patterns:
Model View Controller
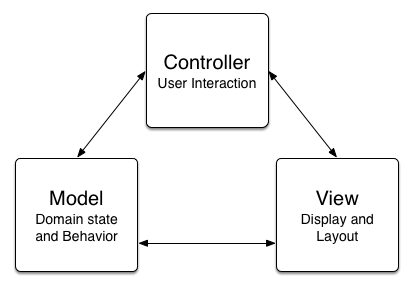
True Model View Controller, as imagined in the Smalltalk world, is defined by three components that, crucially, each talk to both of the others. Models and Views with direct interaction! If someTableViewCell.object = object makes you gag, then you should definitely not be calling your work “MVC”. Controllers here exist to capture user input, but not update the views and models (they do that using their own connection).
Model 2
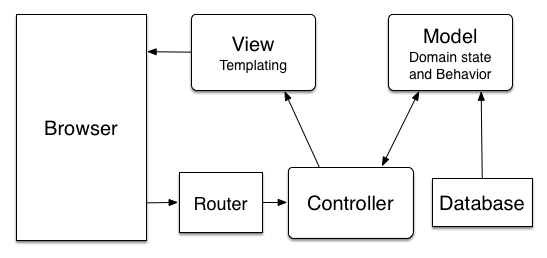
Rails-land behaves a little bit differently. The basic architecture originates from Java-based servers and is called Model 2. Because all of the user inputs come in the form of page requests, those are routed through the Controller as “actions”, which massage the Models and send the data over to the Views. The Views render a response as output and return that to the browser.
Model View Adapter
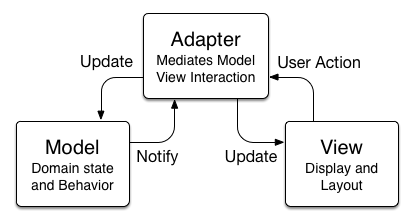
In Objective-C, the pattern that we generally call MVC is more precisely referred to as Model View Adapter. In this system, Models and Views have no direct interaction, and actions (in the form of IBActions, target-actions, KVO observation, delegate calls, and NSNotifications ) flow through the Adapter and update the relevant Models and Views.
Funneling all these different actions through a single object (the view controller) will result in a giant class, jokingly referred to as a Massive View Controller. It’s no wonder that the largest view controller in Brent Simmons’s Vesper codebase is 2900 lines long. You can tell a Ruby developer about a class with 3,000 lines of code, but not without fetching them a fresh pair of underwear first. Objective-C certainly is verbose, but verbosity can’t explain a god class.
I could talk about Massive View Controller for quite a while, so I will leave the discussion of that for another day/blogpost series/anthology.
MVVM
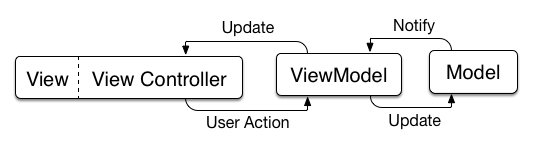
Model-View-ViewModel, hailed as a savior to Massive View Controller, does address some of the problems we face. Ash Furrow wrote a great writeup on the Teehan+Lax blog about MVVM. The View Controller is more formally bound to the View Layer (as it should be, since it’s really a View-level object). A new layer is inserted between the Model and the View couplet, called the View Model, and it is in charge of storing all of the presentation logic for a given view. Other texts might call this the Presenter pattern, which is a name I like, since it doesn’t include the name of both of the other components in the triad.
VIPER
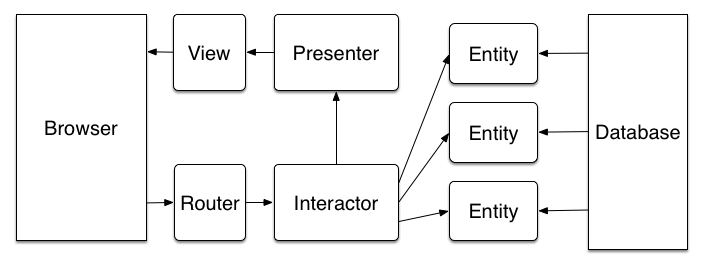
The great thing about programming is that you can do whatever you want. Don’t be bound by ideology or mythology. If we can add a new layer between our View/View Controller combo and our Model, why can’t we add some more layers? VIPER — View-Interactor-Presenter-Entity-Router — attempts to do just that.
The Model is renamed Entity, probably to make a contrived acronym
The Router handles sending a requested “action” to the relevant Interactors
Interactors (also sometimes called Service Objects) represent all business logic involving multiple Entities
Presenters prepare data for display
The View is now dumb as rocks
A small note: Interactors differ from classic Rails controllers in that they’re not bound to a Model (the way UsersController might be tied to the User model), but instead perform some task that involves one or more Entities. Controllers might still exist in this world to receive an action from the router and kick off the relevant Interactors or fetch data from the database.
The best part about adding more layers like this? Each layer, now with a specific role, is way more testable, and the View, usually the hardest layer to test, is now so dumb it doesn’t need unit testing.
So where does this leave us?
Primarily, it leaves us with a language for describing the patterns that we use on a day-to-day basis. What pattern is most appropriate for your app? That’s going to have to be for you to decide. Do you have a Model whose properties require a lot of transforming before display? Take that transformation code out of your View Controller, or — worse — your View, and place it in a Presenter object. A complex interaction between two Models might go in an Interactor. A table view that shows variable content might need a custom Data Source that knows how to manage all of its various states. An app that has content on each View Controller that could link to any other View Controller might need a Router. The possibilities are endless, and the only thing standing between you and your well-factored application is the New Class dialog.
Further reading and watching:
Gang of Four: I’m still working my way through this text, but it has a lot of the prototypical versions of a lot of these patterns.
Patterns of Enterprise Application Architecture: A more practical resource for this day and age, this one practically reads as a cookbook for a framework like Rails.
Refactoring: A great way to think about how to improve your application’s architecture after it’s been built.
collective/interactor: A simple Ruby Gem implementing the Interactor pattern.
Architecture: The Lost Years: A talk from a Ruby conference in 2011, describing the similar issues that our Ruby-focused brothers and sisters are facing. 65 minutes.
I’ll leave you with Graham Lee:
When you get overly attached to MVC, then you look at every class you create and ask the question “is this a model, a view, or a controller?”. Because this question makes no sense, the answer doesn’t either: anything that isn’t evidently data or evidently graphics gets put into the amorphous “controller” collection, which eventually sucks your entire codebase into its innards like a black hole collapsing under its own weight.
Sizing text in a cell is a very common activity. Unfortunately, it’s also very expensive and will undoubtedly cause lag in your scrolling. Usually, that code lives in the -layoutSubviews and looks something like this:
CGSize nameTextSize = [self.textLabel sizeThatFits:CGSizeMake(self.contentView.bounds.size.width, CGFLOAT_MAX)];
N.B.: We could give the string a font and get a size from it (with -sizeWithFont: ), but that doesn’t take into account the specific metrics that the label might be imposing, any internal padding, or any future changes (such as in iOS 6, when UILabels started being able to support attributed strings). So we directly get the size from the label with whatever the current text is.
Let’s hide this behind a method to make it easier to work with:
- (CGSize)sizeForNameLabel {
CGSize nameTextSize = [self.textLabel sizeThatFits:CGSizeMake(self.contentView.bounds.size.width, CGFLOAT_MAX)];
}
Of course, the whole goal is to limit the cost of this method. We have a number that we don’t want to keep calculating over and over, so the obvious solution is to cache it.
What should we use for our cache key? We could try to cache it by the object that’s being represented or the index path or something like that, but our cell really has no knowledge of the object it’s presenting, and (assuming the label’s font and text size stays the same) the important key for caching is the literal text itself. This also lends itself to a natural optimization whenever there is repeated content at different index paths.
Where should we cache it? Our cache key is a string, which lends itself to a dictionary structure for the cache, and fortunately Apple provides us with a self-flushing dictionary-like object for caching, called NSCache. Let’s set up a static NSCache for our text label:
static NSCache *nameLabelSizeCache;
nameLabelSizeCache = nameLabelSizeCache :? [[NSCache alloc] init];
Finally, we make sure to hit the cache before trying to calculate the size, and if it doesn’t exist, calculate the size and return it.
if ([nameLabelSizeCache objectForKey:self.textLabel.text]) {
return [[nameLabelSizeCache objectForKey:self.textLabel.text] CGSizeValue];
}
If we don’t have anything in the cache, that’s when we have to do the expensive calculation, store it in the cache (with the key as a copy of the text, since NSCache doesn’t copy keys), and return the calculated value.
CGSize nameTextSize = [self.textLabel sizeThatFits:CGSizeMake(self.contentView.bounds.size.width, CGFLOAT_MAX)];
[nameLabelSizeCache setObject:[NSValue valueWithCGSize:nameTextSize] forKey:[self.textLabel.text copy]];
return nameTextSize;
A pretty straightforward technique. Because of the static nature of the cache, it’s harder to generalize for all text labels, so you’ll need one cache for each label in the cell, but it’s a pretty quick performance win when sizing in table cells.
The whole method:
- (CGSize)sizeForNameLabel {
static NSCache *nameLabelSizeCache;
nameLabelSizeCache = nameLabelSizeCache :? [[NSCache alloc] init];
if ([nameLabelSizeCache objectForKey:self.textLabel.text]) {
return [[nameLabelSizeCache objectForKey:self.textLabel.text] CGSizeValue];
}
CGSize nameTextSize = [self.textLabel sizeThatFits:CGSizeMake(self.contentView.bounds.size.width, CGFLOAT_MAX)];
[nameLabelSizeCache setObject:[NSValue valueWithCGSize:nameTextSize] forKey:[self.textLabel.text copy]];
return nameTextSize;
}
I wrote a short, inflammatory post a few days ago about Reactive Cocoa not adding much to the tools that we have. This caused a similarly snarky response from a fellow NYC iOS developer, and then a longer, more well-thought-out response as well. I think he deserves an equally clear answer from me. I’d also like to link to this gist, which has a better-written Reactive version of the sample that I quoted.
I want to note to the creators of Reactive Cocoa that I know exactly what it’s like to write something awesome and have random assholes from the internet shit on it. For that, I’m sorry.
For a tool that is loudly heralded as the future, most of the blog posts and code samples focus on how to use the technique, not how it’s better. This is why I published my blog post. My esteemed colleague blogged,
Please, go and try to actually make something with it.”
and
“Believe me when I say: this was a huge win.”
These aren’t convincing explanations of why one technique is better than another. When we saw AFNetworking, we quickly saw how much better it was then anything we’d used for networking up to that point. When we saw the GCC scoping technique, it was immediately obvious how we would use it to write clearer, better-scoped code. After reading Practical Object-Oriented Design in Ruby, I understood how my previous coding practices were bad and what I needed to do to improve them.
Further, the astute reader of this blog will note that my original post didn’t say delegate callbacks were “easier”, it said “better”. “Better” involves more type-checking. “Better” involves looser coupling. “Better” involves semantic names. “Better” involves more clarity, for which I rely on PEP 20. PEP 20 outlines several rules, such as “Beautiful is better than ugly” and “Flat is better than nested”. The application of these tendencies leads to code that easier to reason about.
Beyond the fact that deeply-nested code is hard to reason about and rac_liftSelector: is an ugly method, Objective-C in particular is a bad place to shoehorn FRP into. There are two important reasons for this.
Objective-C was designed for objects, and it is extremely good at them. Of all of the object-oriented languages, I find Objective-C very enjoyable to work with. It’s dynamic and flexible like Ruby but maintains order through its compiler and type-checking.
We Objective-C developers seem to have forgotten what objects really are, with this Massive View Controller problem that faces us. Functional Reactive Programming is definitely one way to deal with this problem, but I maintain that programming with real objects is another, perfectly effective way. In addition, object-oriented programming falls more in line with the analyzer and compiler’s expectations, giving us more type safety and double-checking our work.
The other reason that FRP doesn’t work as well in Objective-C is that blocks are really, really bad. The
__weaking dance is incredibly annoying and reminds me of the pre-ARC days, except more complex and specific. It’s possible to write code that wiggles around having to__weakand__strongobjects, but it requires more thought than it really should have to.There are more signs that working with blocks is hard in Objective-C. Consider the
__blockspecifier. Requiring special behavior to change a primitive or a pointer inside a block shows just how weird this block syntax really is. And that’s ignoring the weird caret (^) and parenthesis rules you have to follow that make me go to fuckingblocksyntax.com every day. These things may change in the future of Objective-C, but Reactive Cocoa is here now.
I have no doubt that FRP is a new, fun, and exciting way to write code. I’m going to give it a deeper look and try to build something with it, as Chris suggested. Whether it’s worth it to start building all apps in it still remains unproven.
Update: More reasoning here.
I was reading a Big Nerd Ranch article on ReactiveCocoa, and I still don’t quite get it.
Lifting a simple example from their post, are we really down to say that
- (void)viewDidLoad {
[super viewDidLoad];
UIRefreshControl *refreshControl = [[UIRefreshControl alloc] init];
@weakify(self);
[[refreshControl rac_signalForControlEvents:UIControlEventValueChanged] subscribeNext:^(UIRefreshControl *refreshControl) {
@strongify(self);
[topQuestionsSignal subscribeNext:^(NSArray *questions){
[self loadQuestions:questions];
} error:^(NSError *error) {
[self displayError:error.localizedDescription title:@"An error occurred"];
[refreshControl endRefreshing];
} completed:^{
[refreshControl endRefreshing];
}];
}];
self.refreshControl = refreshControl;
}
is better code than:
- (void)viewDidLoad {
[super viewDidLoad];
self.refreshControl = [[UIRefreshControl alloc] init];
[self.refreshControl addTarget:self action:@selector(refresh:) forControlEvents:UIControlEventValueChanged];
}
- (void)refresh:(UIRefreshControl*)refreshControl {
[[RSOWebServices sharedWebServices] fetchQuestionsWithDelegate:self];
}
- (void)webService:(RSOWebServices*)webService fetchedQuestions:(NSArray*)questions {
[self loadQuestions:questions];
[refreshControl endRefreshing];
}
- (void)webService:(RSOWebServices*)webService failedWithError:(NSError*)error {
[self displayError:error.localizedDescription title:@"An error occurred"];
[refreshControl endRefreshing];
}
It seems that people are looking for something new, rather than something good.
Objective-Shorthand is a set of categories on Foundation objects that make long things in Objective-C short.
What types of things can Objective-Shorthand help with?
There are many situations in Cocoa where doing a thing that should be simple is actually very involved. For example, checking if a string matches a regular expression is a 3 line process:
NSRegularExpression *regularExpression = [NSRegularExpression regularExpressionWithPattern:regex options:0 error:nil];
NSUInteger numberOfMatches = [regularExpression numberOfMatchesInString:self options:0 range:NSMakeRange(0, self.length)];
BOOL doesMatch = numberOfMatches > 0;
There are certainly lots of options and power in those lines, but 90% of the time, I just want to know if the string matches the regex:
BOOL doesMatch = [string matchesRegex:regex];
This is what Objective-Shorthand does. A method to find the range of the first match for a given regex is also included:
- (NSRange) rangeOfFirstSubstringMatching:(NSString*)regex;
JSON
Using NSJSONSerialization, you have convert your strings to NSData before deserializing them to arrays and dictionaries. Objective-Shorthand simplifies all that.
It provides the same interface as JSONKit, but it works with the built-in Apple JSON serializer behind the scenes. The Ruby community is very good at writing libraries with consistent interfaces, and this is something we need to steal as writers of Objective-C.
To convert from a JSON string to an NSArray or NSDictionary :
- (id) objectFromJSONString;
And to convert from an array or dictionary to an NSString :
- (NSString *)JSONString;
NSComparisonMethods
The OS X SDK has a weird API called NSComparisonMethods. Basically, this API provides a wrapper around compare: and uses it define the following methods:
- (BOOL)isEqualTo:(id)object;
- (BOOL)isLessThanOrEqualTo:(id)object;
- (BOOL)isLessThan:(id)object;
- (BOOL)isGreaterThanOrEqualTo:(id)object;
- (BOOL)isGreaterThan:(id)object;
- (BOOL)isNotEqualTo:(id)object;
For some reason, this never made it over to iOS, even though it’s tremendously useful. I like these methods because they’re way more semantic than the regular compare: method. [object isGreaterThan:otherObject] is way easier to understand than [object compare:otherObject] == NSOrderedDescending.
If the object in question doesn’t respond to compare:, an exception will be thrown.
Data Detection Convenience Methods
NSDataDetector can be a handful sometimes. Objective-Shorthand simplifies complex NSDataDetector that take a few complex lines of code:
NSDataDetector *dataDetector = [NSDataDetector dataDetectorWithTypes:NSTextCheckingTypeDate error:nil];
NSTextCheckingResult *firstMatch = [dataDetector firstMatchInString:self options:0 range:NSMakeRange(0, self.length)];
return firstMatch.range.location == 0 && firstMatch.range.length == self.length;
and simple to one short method call:
- (BOOL) isDate;
- (BOOL)isEmail, - (BOOL)isURL, - (BOOL)isPhoneNumber, and - (BOOL)isAddress are available, too.
NSArray Convenience Methods
Pulling out the unique elements of an array involves the ever-goofy [array valueForKeyPath:@"@distinctUnionOfObjects.self"]. This is wrapped up inside of the following method:
- (NSArray*) uniquedArray;
You never have to remember how to type that string literal again! Autocomplete Rules Everything Around Me.
- (NSArray*)sortedArray and -reversedArray are also in Objective-Shorthand.
Functional Collection Operators
Finally, Objective-Shorthand provides categories on NSArray, NSDictionary, and NSSet that provide the normal functional collection operators, like map, select, and any, but with names that are both more semantic and more native to Objective-C. For me, this means I never have to look up what match: means, ever again.
each is already defined in Foundation, so it is not included.
- (void)enumerateObjectsUsingBlock:(void (^)(id obj, NSUInteger idx, BOOL *stop))block;
Filtering by block with select (aka filter ) and reject can be bound:
- (NSArray*) arrayBySelectingObjectsPassingTest:(BOOL (^)(id object))test;
- (NSArray*) arrayByRejectingObjectsPassingTest:(BOOL (^)(id object))test;
map (aka collect ) and reduce (aka inject ) are available as well.
- (NSArray*) arrayByTransformingObjectsUsingBlock:(id (^)(id object))block;
- (id) objectByReducingObjectsIntoAccumulator:(id)accumulator usingBlock:(id (^)(id accumulator, id object))block;
sample and match are available.
- (id) firstObjectPassingTest:(BOOL (^)(id object))test;
- (id) randomObject;
And finally, some boolean operators:
- (BOOL) allObjectsPassTest:(BOOL (^)(id object))test;
- (BOOL) anyObjectsPassTest:(BOOL (^)(id object))test;
- (BOOL) noObjectsPassTest:(BOOL (^)(id object))test;
All of the above methods with respective changes are also included for NSSet and NSDictionary.
Using Objective-Shorthand
Use Cocoapods to get Objective-Shorthand:
pod 'Objective-Shorthand', '~> 1.0'
Find Objective-Shorthand on GitHub at https://github.com/khanlou/Objective-Shorthand/.
If you have questions, comments, or suggestions, please get in touch. You can find me on Twitter at @khanlou and email at soroush@khanlou.com.
I would normally title this something more clever, but I want this post to be findable by people who are looking for exactly this. Thus, we stick to the convention.
KVO, or key-value observing, is a pattern that Cocoa provides for us for subscribing to changes to the properties of other objects. It’s hands down the most poorly designed API in all of Cocoa, and even when implemented perfectly, it’s still an incredibly dangerous tool to use, reserved only for when no other technique will suffice.
What makes KVO so bad?
I want to run through a few ways that KVO is really problematic, and how problems with it can be avoided. The first and most obvious problem is that KVO has a truly terrible API. This manifests itself in a few ways:
KVO all comes through one method
Let’s say we want to observe the contentSize of our table view. This seems like a great use for KVO, since there’s no other way to get at the information about this property changing. Let’s get started. To register for updates on an object’s property, we can use this method:
- (void)addObserver:(NSObject *)observer forKeyPath:(NSString *)keyPath options:(NSKeyValueObservingOptions)options context:(void *)context
Seems simple enough, self is the observer and the keyPath is contentSize. No clue what those other parameters do, so let’s leave them alone for now.
[_tableView addObserver:self forKeyPath:@"contentSize" options:0 context:NULL];
Great. Now let’s respond to this change:
- (void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary *)change context:(void *)context {
[self configureView];
}
Awesome. We’re done. Just kidding. We have no control over the signature of this method, and it must handle all of our KVO listeners. We should make sure that we’re only responding to our own KVO notification, so we’re not doing extra work.
- (void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary *)change context:(void *)context {
if (object == _tableView && [keyPath isEqualToString:@"contentSize"]) {
[self configureView];
}
}
KVO is string-ly typed
The @"contentSize" key path is string-ly typed. This means that we’re not providing the compiler or the analyzer with any information about what kind of property it is or whether it even exists, and the compiler can’t know to change it when we run the Refactor > Rename command. It’s just a string. (Cool thing that I learned, Refactor > Rename actually does change strings in the -valueForKey: method. There’s still no way to get real type information out of the id return value.)
We have to use NSStringFromSelector(@selector(contentSize)) here, to give the compiler hints about whether this property exists and being able to rename it when the time comes. Of course, we can’t do this for key paths that are multiple values deep, such as if we were observing a view controller and wanted to get the content offset of the scrollview, with the key path: scrollview.contentOffset. Since there’s nothing we can do about that, it’s fortunate that this simple case doesn’t have that problem.
- (void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary *)change context:(void *)context {
if (object == _tableView && [keyPath isEqualToString:NSStringFromSelector(@selector(contentSize))]) {
[self configureView];
}
}
KVO requires you to handle superclasses yourself
Great! Well, not yet. We might have a superclass that also implements this method because it has its own KVO listeners. We should also call super to make sure notifications get to it. If we forget to call super at any point, none of the objects in the superclass chain will receive notifications.
- (void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary *)change context:(void *)context {
if (object == _tableView && [keyPath isEqualToString:@"contentSize"]) {
[self configureView];
} else {
[super observeValueForKeyPath:keyPath ofObject:object change:change context:context];
}
}
You should not pass up any observer notifications that you have handled, or else KVO will complain. Note that the docs suggest calling the superclass’s implementation “if it implements it”, implying that NSObject doesn’t implement it. Even though it’s not documented, NSObject does in fact implement it, probably to prevent us from having to worry about this particular problem.
KVO can crash when deregistering
We want to be good citizens, and we want to remove our particular observance on -dealloc, so we call:
[_tableView removeObserver:self forKeyPath:NSStringFromSelector(@selector(contentSize)) context:NULL];
Now, this isn’t strictly necessary, since the table view will probably get deallocated also, and won’t be able to fire any more notifications. Nevertheless, we should take care of this. An important thing to note is that KVO will throw an exception and crash our app if we try to remove the same observance twice. What happens if a superclass were also observing the same parameter on the same object? It would get removed twice, and the second time would cause a crash.
Hm. Maybe this is where the context parameter comes in? That would make sense. We could pass a context like self, which would make perfect sense, since this object is the context. However, this wouldn’t help us in the superclass case (since self would point to the same object in the superclass as well as the subclass). Mattt Thompson at NSHipster recommends using a static pointer that stores its own value for the context, like so:
static void *ClassNameTableViewContentSizeContext = &ClassNameTableViewContentSizeContext;
This should be scoped to our file, so that no other files have access to it, and we use a separate one for each key-value observation we do. This helps to make sure that none of our super- or subclasses can deregister us from being an observer.
We can use this context when registering and then also check it in the observation method. Now that we have contexts, we only want to pass the notification along to super if we didn’t use it ourselves. One nice thing about having a pointer that is specific to this one exact observance is that we can check just this parameter, instead of having to check the object and keypath parameters, simplifying our code.
- (void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary *)change context:(void *)context {
if (context == ClassNameTableViewContentSizeContext) {
[self doThing];
} else if (context == OtherContext) {
[self doOtherThing];
} else {
[super observeValueForKeyPath:keyPath ofObject:object change:change context:context];
}
}
N.B.: We always call out to a different method instead of trying to do our work inside the method, since the observeValueForKeyPath: method will get really gnarly really fast.
KVO is a pit of failure
All of these nuances in the API cause KVO to embody what is known as a pit of failure rather than a pit of success. The pit of success is a concept that Jeff Atwood talks about. APIs should be designed so that they guide you into using them successfully. The should give you hints as to how to use them, even if they don’t explain why you should use them in that particular way.
KVO does none of those things. If you don’t understand the subtleties in the parameters, or if you forget any of the details in implementation (which I had done and only noticed because I went back to my code to reference it while writing this blog post), you can cause horrible unintended behaviors, such as infinite loops, crashes, and ignored KVO notifications.
KVO is implicit
Even if KVO had a great API and were easy to use, it has other problems as well. Rule #2 of Pep 20 is: >
Explicit is better than implicit.
KVO is the implicit way of updating with state changes. Tiny changes in one corner of your app can have ripple effects into other unexpected corners. You have no way of really keeping track of what’s being observed and by whom, and you have no way of using Xcode’s tools, like Command-click, to follow the path of code changes. The only thing you can hope to do is keep all your observations in your head at all times, which falls apart hopelessly as soon your app gets to any meaningful size or you add even one more person to your team.
A reader commented on Twitter with a great phrase that describes the problem exactly: he called KVO “a non-local implicit control flow change”. You’re essentially injecting code into setters at runtime from another object entirely.
When compared with a delegate pattern, KVO shows how weak it is in this area. For example, in most cases, there is only one delegate at any given time, simplifying which objects you need to check when problems arise. Since you have to implement a method with a custom selector, it is very easy to track down which objects in your app can ever even be the delegate for a particular protocol. It also provides casting and type information to its delegates, which reduces your reliance on guessing the type or checking at runtime with isKindOfClass: the way you have to with KVO.
KVO can cause infinite loops
You also have to make sure that you’re not changing the property that you’re observing when you’re responding to it, because then you’ll get another notification, ad infinitum. You never know if you’re changing another property that will also trigger a separate KVO notification, making debugging all the more difficult.
Of course, if you’re taking a lock when using your setter, your observers will be fired with that lock still held. Every time we think we have a grasp on the nuances of KVO, it hits us with a new problem.
Even if we use queues where we used to use locks, the same problem exists here as well. The KVO observer method will be fired on whatever thread the setter was called on, at which point you accidentally update your UI from the main thread, and your UI enters an inconsistent state, and your QA tester files a completely inexplicable bug. NSNotificationCenter has the same problem, but at least you’re explicitly publishing a notification in that case. The sender has control over when that notification gets posted, instead of the sender having no idea that it’s going to be notifying observers until runtime.
Even if something looks KVO-able, it might not be
Something that I didn’t realize until after I published the post, just because something uses an @property doesn’t mean it’s okay to observe with KVO. In this particular example, observing the table view’s contentSize happens to work, but if the ivar was being manipulated underneath the hood, you wouldn’t get KVO notifications, and KVO would enter an inconsistent state.
Weak properties are KVOable, and this is made to work by the framework inserting an intermediary observer, which is not cleaned up when the __weak object gets deallocated. This causes you to attempt to access a dereferenced pointer, which causes a crash. This is a known bug. You also don’t get a notification when the weak pointer is nilled out, reducing some of the usefulness of KVO.
KVO is the old way
Back in 2005, the observer pattern was the way to go for model changes. Everyone wrote Java: controls would update models, which would be listened to by controllers, and the pattern reigned. At some point, programmers began to see the shortcomings in this pattern, and started using more explicit patterns, such as delegation, closure callbacks, and more explicit pub/sub (like NSNotificationCenter, which of course has some of these flaws, but at least has a decent API that doesn’t screw you up at every turn).
The evidence of KVO being a relic of times gone by is plentiful. For example, when making apps for the Mac, you can use a tool called Cocoa Bindings. Bindings are a tool that use KVO to “bind” part of an object, like a property called “name” to a text field that would be used to edit the “name” property. Since these are “bound” together, changes to the model would cause the text field to update, and changes to the text field would cause the model to update.
This sounds useful, but it doesn’t exist in the Cocoa Touch API, for a few reasons. Bindings were slow, bindings are hard to debug because of their implicit nature, and with fewer view controllers on screen, they are less important. The movement away from this pattern is telling, though.
When is it okay to use KVO?
When I program, I consider only 2 cases acceptable for KVO.
When Apple requires it. A great example of this is in the
AVPlayerclass. Apple requires in the documentation that you observe thestatusproperty to be given info on when the player’s status isAVPlayerStatusReadyToPlay. Like in scenario 1, you’re given no other option and have to observe to get this information out. In cases like this, I usually wrap it up in another class, possibly with a delegate or a block callback, and use that instead.Designing an API for someone else. If you are designing a tool for public use, and you want to be informed of
scrollViewDidScroll:notifications, but you don’t want to prevent the users of your library from being the delegate of the scrollview, you can observecontentOffsetinstead. This can run you afoul of KVOing on properties that aren’t explicitly documented as KVO-able, but it can’t be helped.
Update: While this does work, the Apple documentation says that this behavior is undefined:
The predicate must point to a variable stored in global or static scope. The result of using a predicate with automatic or dynamic storage (including Objective-C instance variables) is undefined.
Update II: Using OSMemoryBarrier() makes this behavior fully defined.
Ben Stiglitz wrote in with a suggestion. Using OSMemoryBarrier() in the initializer of your object makes sure that it is globally visible (i.e., from any thread) before any code that references it executes.
Original Post:
Every use of dispatch_once that I’ve seen across the web has been for setting up singletons by using a static token to make sure the initialization code only runs once per session of the app.
+ (instancetype) sharedInstance {
static dispatch_once_t onceToken;
static id sharedInstance;
dispatch_once(&onceToken, ^{
sharedInstance = [[self alloc] init];
});
return sharedInstance;
}
This is a great technique, but I’ve been looking for a way to use dispatch_once once per instance instead of once per class, but it’s no really clear how to adapt the singleton technique for a per-instance technique. I hacked around with a new project today and figured it out. It ends up being about as straightforward as you would expect.
@interface MyClass ()
@property (nonatomic, assign) dispatch_once_t onceToken;
@end
Declare a dispatch_once_t single use token in your class’s extension, and use that for running the code you only want to run once (such as initialization).
- (void) setupThing {
dispatch_once(&_onceToken, ^{
//set up thing
});
}
You can now call this method as many times as you want (per instance) from any thread, and it will only be run once.
UITableView has built-in methods for adding and removing cells with animations, but it has no way of peeking into your data source to understand how it has changed. Understanding which elements in a list were removed, which stayed the same, and which were added, seems like a thing computers would be really good at. It turns out, it is.
The technique is called the Longest Common Subsequence. I wrote a category on NSArray to calculate this. For the actual algorithm, I used a bottom-up dynamic programming solution, with results cached in a C matrix. It isn’t terribly complex, and I shamelessly stole my implementation from this page. You can also read a more in-depth explanation on Wikipedia.
The algorithm operates in O(mn) time, where m and n are the lengths of the two arrays. Determining the equality of objects is done through the isEquals: method, so be sure that your implementation of that method represents equality for your objects.
Adaptation
In adapting this algorithm for Cocoa, I took advantage of NSIndexSet, which is a great class that lets you store a group of unique indexes. Returning NSIndexSets gives you the benefit of being able to call -[NSArray objectsAtIndexes:] to easily get access to the objects themselves.
Building the table of the lengths of common subsequences is the first step. Once we have our table of subsequence lengths, we can backtrack through it to get the indexes of the common objects. This technique is documented in a few places, including both of the links above. If all you need is the common indexes, there is a convenience method for you:
- (NSIndexSet*) indexesOfCommonElementsWithArray:(NSArray*)array;
Of course, this is Cocoa, and we want to be able to use this information with UIKit, namely, UITableView and UICollectionView. If we can figure out what format the data should be for the -insertRowsAtIndexPaths:withRowAnimation: and -deleteRowsAtIndexPaths:withRowAnimation: methods, we can really easily transform from any arbitrary array to any other array.
For this, a second method is provided. It has two inout parameters that return the extra data that is needed.
- (NSIndexSet*) indexesOfCommonElementsWithArray:(NSArray*)array addedIndexes:(NSIndexSet**)addedIndexes removedIndexes:(NSIndexSet**)removedIndexes;
You can see that a sample implementation (for any general case of data!) is pretty simple.
NSIndexSet *addedIndexes, *removedIndexes;
[oldData indexesOfCommonElementsWithArray:newData addedIndexes:&addedIndexes removedIndexes:&removedIndexes];
self.dataSource = newData;
NSMutableArray *indexPathsToAdd = [NSMutableArray array], *indexPathsToDelete = [NSMutableArray array];
[addedIndexes enumerateIndexesUsingBlock:^(NSUInteger idx, BOOL *stop) {
[indexPathsToAdd addObject:[NSIndexPath indexPathForRow:idx inSection:0]];
}];
[removedIndexes enumerateIndexesUsingBlock:^(NSUInteger idx, BOOL *stop) {
[indexPathsToDelete addObject:[NSIndexPath indexPathForRow:idx inSection:0]];
}];
[_tableView beginUpdates];
[_tableView insertRowsAtIndexPaths:indexPathsToAdd withRowAnimation:UITableViewRowAnimationAutomatic];
[_tableView deleteRowsAtIndexPaths:indexPathsToDelete withRowAnimation:UITableViewRowAnimationAutomatic];
[_tableView endUpdates];
Calculation of the added and removed indexes
The key to finding the right indexes was (as always) in the Apple documentation:
[
UITableView] defers any insertions of rows or sections until after it has handled the deletions of rows or sections.
This means the deleted objects have to be found first. Once they’ve been removed, we have only the common objects left. We can then compare the new array to the list of common objects, and find the indexes that the new tableview rows will need to be added at.
One caveat is that UITableView doesn’t like when you try to add two insert animations for the same row, so we increment by one if that index is already in the addedIndexes set.
Source
The source can be found on GitHub. Pull requests are encouraged, but make sure that the tests are all passing before submitting a pull request.
It feels like the state of the art for creating singletons changes every year. The (somewhat) new hotness is to use dispatch_once to create them:
+ (instancetype) sharedInstance
{
static dispatch_once_t onceToken;
static id sharedInstance;
dispatch_once(&onceToken, ^{
sharedInstance = [[self alloc] init];
});
return sharedInstance;
}
(I use instancetype (read more) here but please don’t ever subclass singletons. It won’t end well.)
This works great: dispatch_once is fast, mostly because it doesn’t require any locks. GCD handles all of the heavy lifting.
The problem arises if you ever want to assert that there is only ever one instance of this singleton. If you use this code, it will provide a shared instance of the class that is globally accessible, but any other consumer of the code will be able [[Singleton alloc] init] their way into a new instance, which could be problematic, depending on how you want your code to be used.
Usually, the check to make sure that no other instances are created is handled in +alloc and to make sure that it is thread-safe, it is wrapped in an @synchronized block.
static typeof(self) _sharedInstance = nil;
+ (instancetype)sharedInstance
{
@synchronized(self){
if (!_sharedInstance) {
_sharedInstance = [[self alloc] init];
}
return _sharedInstance;
}
return nil;
}
+ (id)alloc
{
@synchronized(self){
NSAssert(_sharedInstance == nil, @"Attempt to allocate a second instance of singleton %@", [self class]);
_sharedInstance = [super alloc];
return _sharedInstance;
}
return nil;
}
We don’t want to use @synchronized however, since we’re moving away from locks and towards queues. What we need a way to be able to alloc ourselves, without allowing external classes to alloc.
The solution I came up with for this is to called [super allocWithZone:nil] in our accessor, and overriding +allocWithZone: in the singleton to raise an exception.
+ (instancetype) sharedInstance
{
static dispatch_once_t once;
static id sharedInstance;
dispatch_once(&once, ^{
sharedInstance = [[super allocWithZone:nil] init];
});
return sharedInstance;
}
+ (id) allocWithZone:(NSZone *)zone {
NSString *reason = [NSString stringWithFormat:@"Attempt to allocate a second instance of the singleton %@", [self class]];
NSException *exception = [NSException exceptionWithName:@"Multiple singletons"
reason:reason
userInfo:nil];
[exception raise];
return nil;
}
This way, anyone trying to access from the outside will call +alloc, which will call +allocWithZone, which will crash the app. My understanding is also that zones are basically deprecated, and every app only has one zone anyway, making it okay to pass nil in for that parameter.
If there’s a better solution for this, I’d love to hear about it. @khanlou or soroush@khanlou.com
Update: Alejandro Ramirez ((@j4n0) wrote in to share a different way to handle the same thing: adding compiler errors for when init, copy, and new are called. In your header file:
+(instancetype) sharedInstance;
// clue for improper use (produces compile time error)
+(instancetype) alloc __attribute__((unavailable("alloc not available, call sharedInstance instead")));
-(instancetype) init __attribute__((unavailable("init not available, call sharedInstance instead")));
+(instancetype) new __attribute__((unavailable("new not available, call sharedInstance instead")));
You can find all the code on his gist.
