“Telling a programmer there’s already a library to do X is like telling a songwriter there’s already a song about love.” - Pete Cordell
Sometimes, it feels like questions that arise during my time programming take years to answer. In particular, my journey to a web framework that I vibe with has been a long one.
A few years ago, I wrote about trying to squeeze the behavior I want out of Vapor. I (rather poorly) named the concept Commands, and I wrote a blog post about the pattern.
Generally speaking, this style of routing, where you use a closure for each route, has been used in frameworks like Flask, Sinatra, and Express. It makes for a pretty great demo, but a project in practice often has complicated endpoints, and putting everything in one big function doesn’t scale.
Going even further, the Rails style of having a giant controller which serves as a namespace for vaguely related methods for each endpoint is borderline offensive. I think we can do better than both of these. (If you want to dig into Ruby server architecture, I’ve taken a few ideas from the Trailblazer project.)
Here’s what the Command protocol basically looked like:
protocol Command {
init(request: Request, droplet: Droplet) throws
var status: Status { get }
func execute() throws -> JSON
}
(This is Vapor 2 code, so I think the above code won’t compile with modern versions of Vapor. RIP to “droplets”.)
The Command protocol represented an instance of something that responds to a request. There was a lot I liked about the Command pattern. It was one object per request, meaning each object had strong sense of self, and the code was always nicely structured and easy for me to read.
However, it had some downsides. First, it was tacked on to Vapor. There was a fair bit of code to ensure that things stayed compatible with Vapor, and when they released an update, I was obliged to migrate all my stuff over as well.
In addition, the initializers for Commands always had a ton of work in them:
public init(request: Request, droplet: Droplet) throws {
self.apnsToken = try request.niceJSON.fetch("apnsToken")
self.user = try request.session.ensureUser()
}
Anything you needed to extract out of the Request had to be done here, so there was always a lot of configuration and set up code here. For complex requests, this gets huge. Another subtle thing — because it relies on Swift’s error handling, it can only ever report one error.
This initialization code looks to me like it could get simpler still, and with a little configuration, you could get the exact results you wanted, good errors if something went wrong, and a hefty dose of optimization that I could sprinkle in by controlling the whole stack.
Meridian
Enter Meridian.
struct TodoDraft: Codable {
let name: String
let priority: Priority
}
struct CreateTodo: Responder {
@JSONBody var draft: TodoDraft
@EnvironmentObject var database: Database
@Auth var auth
func execute() throws -> Response {
try database.addTodo(draft)
return try JSON(database.getTodos())
.statusCode(.created)
}
}
Server(errorRenderer: JSONErrorRenderer())
.register {
CreateTodo()
.on(.post("/todos"))
}
.environmentObject(try Database())
.listen()
Property Wrappers
Meridian uses property wrappers to grab useful components from the request so that you can work them into your code without having to specify how to get them. You declare that you want a @JSONBody and give it a type, it handles the rest:
@JSONBody var draft: TodoDraft
Because the value is a non-optional, when your execute() function is called, you’re guaranteed to have your draft. If something is wrong with the JSON payload, your execute() function won’t be called (because it can’t be called). You deal in the exact values you want, and nothing else.
You want a single value from the JSON instead, because making a new Codable type to get a single value is annoying? Bam:
@JSONValue("title") var title: String
You can make the type of title be optional, and then the request won’t fail if the value is missing (but will fail if the value is the wrong type).
URL parameters: very important. Sprinkle in some type safety, and why don’t we make them named (instead of positional) for good measure?
@URLParameter(\.id) var id
Query parameters, including codable support for non-string types:
@QueryParameter("client-hours") var clientHours: Double?
A rich environment, just like SwiftUI, so you can create one database and share it among many responders.
@EnvironmentObject var database: Database
You can use EnvironmentValues for value types or storing multiple objects of the same type.
@Environment(\.shortDateFormatter) var shortDateFormatter
The cherry on top? You can define your own custom property wrappers that can be used just like the first-class ones. I’ve primarily been using this for authentication:
@Auth var auth
You can define them in your app’s module, and use it anywhere in your app, just like a first class property wrapper.
All of these property wrappers seek to have great errors, so users of your API or app will always know what to do to make things work when they fail.
It’s a real joy to simply declare something at the top of your responder, and then use it as though it were a regular value. Even though I wrote the code, and I know exactly how much complexity goes into extracting one of these values, there’s still a magical feeling when I write @QueryParameter("sortOrder") var sortOrder: SortOrder and that value is available for me to use with no extra work from me.
Outgoing Responses
Property wrappers represent information coming in to the request. However, the other side of Meridian is what happens to data on the way out.
For this, Meridian has Responses:
public protocol Response {
func body() throws -> Data
}
Responses know how to encode themselves, so JSON takes a codable object and returns JSON data. All the user does is return JSON(todos) in their execute() function, and the data is encoded and relevant headers are attached.
EmptyResponse, Redirect, and StringResponse are all pretty straightforward. It’s also not too hard to add your own Response. In one project, I needed to serve static files, so I added a File response type.
struct File: Response {
let url: URL
func body() throws -> Data {
try Data(contentsOf: url)
}
}
This might get more advanced in the future (maybe we could stream the file’s data, let’s say), but this gets the job done.
Responses are a type-aware way of packaging up useful common behavior for data coming out of a request.
Where things are headed
Meridian is nowhere close to done. I’ve written three different JSON APIs with it and a rich web app (using Rob Böhnke’s Swim package to render HTML). The basic concepts are working really well for me, but there’s quite a few things it doesn’t do yet.
Parsing multipart input
Serving static files
Side effects (like the aforelinked Commands)
Localization
HTML nodes that can access the environment
Middleware?
Meridian also knows so much about the way your requests are defined that it should be able to generate an OpenAPI/Swagger spec just from your code, which would be an amazing feature to add.
Meridian is currently synchronous only. The options for async Swift on the server are not great at the moment (because you either end up exposing NIO details or rewriting everything yourself). I’d rather have the migration to async code be as simple as putting await in front of everything, instead of changing all of your code from a block-based callback model to a flat async/await model. I’m focused more on developer experience than sheer request throughput.
I also have a lot of docs to write. I also wrote some docs.
While it’s a bit passé to not blog for over a year, and then dive right back in by talking about your blog setup, I’m going to do it anyway. I recently moved all of my static sites and Swift services over to Dokku, and I am really enjoying it.
Dokku is a collection of shell scripts that act as a self-hosted platform-as-a-service. Basically, it’s your own personal Heroku. Chris and I actually discussed it a few years ago on an episode of Fatal Error. I’ve wanted to move my stuff to it for a while, and finally spent some time over the break getting things moved over.
First, I want to run down how things were running before, and why I wanted something like Dokku. First, I manage 4 static sites, including this one. I, through painful trial/error/googling, carefully set up nginx virtual hosting to host all 4 sites on a single Linode instance. I also run 4 git remotes on that server, with clever post-receive hooks that accept pushes, do bundle install and jekyll build (when appropriate) and copy the HTML files to their final destination. This works pretty well and feels Heroku-esque (or Github pages-esque, if you like). I git push, and the rest happens for me automatically. I particularly like this model because it hits the trifecta — I get to host the site myself, I get to use Jekyll (including plugins!), and its interface is just a simple git push. I can even push changes from my phone using Working Copy.
Recently, I also started running a Swift API for a chore app for me and my girlfriend. I hope to blog more about this app soon for a few reasons, not least of which is that I wrote my own property wrapper-based web framework on top of Swift NIO, which has been working great.
This API has been running on Heroku. Because only two people use it, it doesn’t really make sense to pay $7/mo for a dyno, especially given that I run 4 static sites for $5/mo on Linode. Heroku does have a free tier they call “Hobby”, but using it incurs a performance penalty — your app spins down if you don’t use it for a little while (about 30 minutes or so?), and spinning back up takes 5-10 seconds. This makes for a pretty intolerable experience in the app. This too was a good candidate for moving to my own infrastructure.
I wrote one more small Swift-based web service for myself, which also shouldn’t have a ton of usage but does need its own Postgres database, and that cinched it. I wanted to move off of this patchwork system onto something more consistent.
I spun up a new Linode instance, installed Dokku, and got to work. Each Dokku site had three major components for me:
Buildpacks
Dokku uses buildpacks and Procfiles, just like Heroku, to describe how to install and run any app. Buildpacks can be set as an environment variable for the app, or included in the repo in a .buildpacks file. For Jekyll sites, you actually need two buildpacks:
https://github.com/heroku/heroku-buildpack-nginx.git
https://github.com/inket/dokku-buildpack-jekyll3-nginx.git
On the other hand, for Swift sites, the default Vapor buildpack works great:
https://github.com/vapor-community/heroku-buildpack
Encryption
Dokku has a concept of “plugins”, which add functionality to Dokku. The Let’s Encrypt plugin worked flawlessly for me. Installing a plugin is easy:
dokku plugin:install https://github.com/dokku/dokku-letsencrypt.git
You install it, set your email as an environment variable, and ask the plugin to add encryption to your site. (DNS for the relevant domains needs to be pointing at the server already for this to work.) Love it.
Databases
The two Swift services both need Postgres. No problem, just one more plugin:
dokku plugin:install https://github.com/dokku/dokku-postgres.git postgres
From the Postgres plugin, you can create databases, link them to apps, expose them to the internet, and manage them as needed.
Debugging
I want to end on one final note about debugging. Dokku itself is not a particularly complex tool, since it delegates all the isolation and actual deployment of code to Docker. (Side question: is it “dock-oo”, because of Docker, or doe-koo, like Heroku? The world may never know.) The reliance on Docker means that it can be really helpful to know how to debug Docker containers.
Two specific tips I have here:
You can
dokku enter my-app-name webto enter the virtualized machine’s console, which can let you explore the structure of things.You can use
docker psto list all the currently running containers, and use that to watch the logs of a build in progress, by usingdocker logs -f <container id>. This is super useful for debugging failing builds. (Big thanks to Sam Gross for giving me some insight here.)
Conclusion
Dokku basically checks all my boxes. I get to run things on my own servers, it’s cheap, and deploys are easy as a git push. I’m paying the same amount as before ($5/mo! I can hardly believe it!) My previously manually managed static sites all have the exact same interface as they used to, with a lot less work from me to set up and manage, and now I’m hosting Swift-backed sites as well. Put one in the W column.
Recently, I’ve been working on a music app that needs to get a musical sequence (like a melody) from the server to the client. To do this, we use a format called ABC. (You can read about how ABC music notation works here.) We chose ABC because it’s more readable than MIDI, it’s pretty concise, and it’s a standard, so we wouldn’t be re-inventing some format over JSON.
ABC is a simple format, and it does a great job of representing music in strings. For example, here’s the little bit from Beethoven’s “Für Elise” that everyone knows:
e ^d e d e B =d c A2
The letters correspond to specific pitches, the characters before the letters represent accidentals (sharps and flats), and the numbers after them represent the duration that that note should be played for. ABC has a lot more features (it supports rests, ties, beams, barlines, and so on), but this simple example gives you a sense for how the format works.
The app needs to transform the string into some kind of struct that the sequencer knows how to play. In short, we need to parse this string.
Regular Expressions
At first blush, the problem seems easy enough. Split on spaces, and write some regular expressions to convert each note into some kind of value. For note parsing, the expression looks something like this:
^(\\^+|_+|=)?([a-gA-G])(,+|'+)?(\\d*)(\\/)?(\\d*)$
There are 3 main problems with this regular expression.
It’s inscrutable
It is nearly impossible to determine what this regex does by looking at it. Especially for something like ABC, which uses punctuation marks for things like accidentals (^, _, and =) as well as octave adjustments (' and ,), it’s really hard to tell which are literal characters that we are trying to match, and which are regex control characters that tell the pattern to match zero or more of this one, optionally match that one, and so on.
One thing I will grant here is that despite their inscrutability, regexes are one of the tersest languages you can write.
It’s not composable
Another problem with regular expressions is that the constituent components don’t compose easily. For example, our Beethoven sequence above doesn’t include any rests, but they typically look like just like a note with a z instead of the letter of the pitch. So for example, a half rest might look like z/2.
Ideally, we’d like to be able to reuse the duration pattern, but it’s currently trapped inside that giant regex. In order to compose these regexes together, we have to break them apart first, and then apply some string concatenation:
let accidentalPattern = "(\\^+|_+|=)?"
let letterPattern = "([a-gA-G])"
let octaveAdjustmentPattern = "(,+|'+)?"
let durationPattern = "(\\d*)(\\/)?(\\d*)"
let restPattern = "z"
let noteRegex = try! NSRegularExpression(pattern: accidentalPattern + letterPattern + octaveAdjustmentPattern + durationPattern)
let restRegex = try! NSRegularExpression(pattern: restPattern + durationPattern
This is really the only way to get composability with regexes. And of course, because these are just strings that we’re concatenating, there’s no way to know if our concatenation represents a valid transformation of the underlying regular expression because it isn’t checked at compile time.
It requires additional conversion
Lastly, even once we have successfully composed our regex pattern, compiled it into a regular expression, and parsed a string, we still don’t actually have anything useful! We have a bunch of capture groups that we need to operate on to get our final result. For example, the first capture group in the regex gives us our accidental string. This can either be one more carets (^) (sharp), one more underscores (_) (flat), or an equals sign (=) (natural), but the regex doesn’t tell us which it is, so we need to parse it further.
let numAccidentals = match.captureGroups[0].text.count
let accidentalChar = match.captureGroups[0].text.first
switch accidentalChar {
case "^":
return .accidental(numAccidentals)
case "_":
return .accidental(-numAccidentals)
case "=":
return .natural
case "":
return Accidental.none
default:
return nil
}
Requiring a manual step where we have to convert the matched substring into our domain object is kind of annoying.
Combinatorial Parsing
My first clue that we needed to look closer at this problem was a function signature. Our strategy for parsing sequences was to consume small pieces of the front of a string. For example, for a note, we’d have something like this:
func consumeNote(abcString: Substring) -> (note: Note?, remainder: Substring)
A function that returns a tuple of (T?, Substring) looked very familiar. I’d seen it referenced in the Pointfree code about combinatorial parsing:
extension Parser {
run(_ str: String) -> (match: A?, rest: Substring)
}
This is called a combinatorial parser because it relates to a somewhat obscure part of computer science called combinators. I don’t understand them fully, but I will kick it over to Daniel Steinberg to share some very cool examples.
I figured if we’re trying to parse text and return something in this format anyway, maybe the combinatorial parser could be a good fit. So I did a little research on the topic and started the process of reimplementing our parsing with this new strategy. The crux of the parser is a struct with a single function:
struct Parser<A> {
let run: (inout Substring) -> A?
}
You give it a string (a substring in this case, for performance reasons) and it consumes characters from the front of the buffer to see if it can construct a generic A from them. If that succeeds, it returns the A. If it fails, it returns nil, ensuring no modifications to the input parameter.
Using parser combinators, it’s possible to write concise, type-safe, composable code that parses strings just as effectively as regexes. For example, here’s how you check for a literal:
static func literal(_ string: String) -> Parser<Void> {
return Parser<Void>(run: { input in
if input.hasPrefix(string) {
input.removeFirst(string.count)
return ()
} else {
return nil
}
})
}
If the input has a prefix of the string we’re looking for, drop that many characters off the front and return a valid value (Void in this case). If not, return nil — no match. I won’t go into detail on all the other helpers here — you can find a lot of them in the Pointfree sample code.
Using this helper and others, you can rewrite the accidental parsing from above into something like this:
let accidentalParser: Parser<Accidental> = Parsers.oneOf([
Parsers.repeating("^").map({ .accidental($0.count) }),
Parsers.repeating("_").map({ .accidental(-$0.count) }),
Parsers.literal("=").map({ .natural }),
Parsers.literal("").map({ .none }),
])
This avoids basically every pitfall that the regex approach has.
First, it’s very readable. You can see what literal characters it’s matching because they’re still strings, but all the regex control characters have changed into named functions, which are approachable for people who aren’t regex experts.
Second, it’s very composable. This parser is made up of smaller parsers, like .repeating or .literal, and is itself composed into bigger parsers, like those for notes, rests, and so on. Here’s the accidental parser in the note parser.
var noteParser: Parser<Note> {
return Parsers.zip(accidentalParser, pitchParser, durationParser)
.map({ accidental, pitch, duration in
return Note(accidental: accidental, pitch: pitch, duration: duration)
})
}
(zip matches all of the parsers that are given to it, in order, and fails if any of them fail.) In this example, it’s also really great to see how all the types line up cleanly. You get a lot of assurance from the compiler that everything is in order.
The last benefit it has over regex is that it produces the actual value that you’re expecting, an Accidental, as opposed to substring capture groups that you have to process further. Especially using the map operation, you can transform simple results, like a substring or Void into domain specific results, like Accidental or Note.
The only real place that this loses out to regexes is terseness, and when you add the transformation code that regexes require, it’s basically a wash.
Now, we’ve completely handrolled a parsing solution from scratch, in pure Swift, using only tools like substrings and blocks. Surely regexes, which are highly tuned and written in C, should be able to massively outperform this code in terms of speed?
Wrong. By using this new approach, we were able to get 25% faster parsing across the board. This shocked me, to be honest. I will usually take a small speed hit if it makes the code nicer (assuming it’s not a critical path, not noticable by the user, etc), but in this case, that wasn’t even a concern, since the nicer code was also the faster code. Win-win! I think a lot of the speed benefit comes from using substrings. Trimming off the front of a substring is effectively free, which makes a lot of these operations super fast.
There are still a few areas which I’d like to learn more about, like unparsing (what if we want to turn our sequence struct back into an ABC string), and how parsers perform when the needle is in an arbitrary place in the haystack, but it’s going to be pretty hard to get me to go back to regexes after these results.
A few years ago, I wrote Implementing Dictionary In Swift, which was a crash course on how to create something similar to Swift’s Dictionary type.
Since our dictionary will be backed with an array, we need a way to convert the key that’s given into an integer, and then a way to force that integer into the bounds of our array. These two methods are the hashing function and the modulus operation, respectively. By hashing, we can consistently turn our key (usually a string, but can be any type that is Hashable) into a number, and by taking the modulus with respect to the length of the array, we’ll get a consistent slot in the array to set and retrieve the value.
Because there can be collisions, each “bucket” needs to potentially contain multiple items, so the whole thing was modeled as an array of arrays. This was a less-than-performant shortcut to get code that was working up quickly. In the post, I noted that:
A nice implementation of this Dictionary might use a linked list for the
valuesproperty of the Placeholder.
Since writing that post, I’ve learned a lot of things, but germane to the discussion here: this is a bad strategy. Linked lists are very good when memory is tightly limited, and you can’t reliably secure a long, unbroken block of memory. As memory in our computers has gotten bigger, CPUs have learned to predict and preload memory in long sequences, so working with continuous blocks of memory is remarkably faster to jumping around the memory space through a discontinuous chain.
So if we don’t want to use an array of arrays, and we don’t want to use an array of linked lists, what else can we do? It turns out that there is a Dictionary storage technique that avoids the problems with both solutions.
If you remember that any array of arrays can be “flattened” into one large array, a solution begins to take shape. If the bucket for a given hash value is taken, instead of storing a second value at the same location, put the new value in the neighboring bucket. Then, when searching for that element, if you see something where it should be, check the neighboring buckets until you find it (or an empty slot).
This technique is called “linear probing”. It was invented in 1954 and is the way that Swift’s Dictionary is actually implemented!
In this post, we’re going to writing a Dictionary that’s backed by linear probing. I’m going to use a test-driven development approach for a few reasons.
First, a key thing in Swift has changed since I wrote the last dictionary blog post. Swift 4.2 changed Swift’s hashing to be non-deterministic. This makes it really hard to write to simple tests in a playground, since any value’s hash changes between runs. We need to tightly control how our hash values are produced so that we can be sure that our Dictionary behaves appropriately as we refactor it.
Second, this algorithm behaves interestingly at the boundaries — that is, as it runs up against the end of the backing array and needs to roll over to the start of the array — and we need to make sure we handle that behavior correctly.
Third, deletion is really, really hard to get right with linear probing, and there are quite a few edge cases that need to be examined closely.
The technique also lends itself to some refactoring and restructuring, and having tests will be a great safety net to ensure that we don’t break old behavior as we make the code cleaner and simpler.
Getting Things Compiling
So, let’s get started. Test-driven development requires that you write a failing test before writing the code that makes it work, so let’s do that here.
func testGettingFromAnEmptyDictionary() {
var dictionary = ProbingDictionary<String, String>()
XCTAssertEqual(dictionary["a"], nil)
}
This test doesn’t compile, so we can call that failing. Let’s build the basics of the type and get this test passing.
struct ProbingDictionary<Key: Hashable, Value> {
subscript(key: Key) -> Value? {
get {
return nil
}
set {
}
}
}
Not a very good dictionary, but at least it compiles and passes the first test.
Getting and Setting a Single Value
Next, let’s get it to be able to set and then get a single value. Test first:
func testSettingAndGettingAValue() {
var dictionary = ProbingDictionary<String, String>()
dictionary["a"] = "123"
XCTAssertEqual(dictionary["a"], "123")
}
(The most hardcore TDD acolytes will change the implementation so that it can store exactly one value, probably in an instance variable, since that’s the bare minimum of code that you need to make this test pass. I think that’s kind of silly, so I will skip that step and jump straight to an implementation that works with multiple values.)
For the implementation, we need a few things already. We need some kind of Placeholder type again, like in the last post. However, instead of being able to store an array of key/value pairs, it’ll just store a key and a value, or nothing:
enum Item {
case element(Key, Value)
case empty
}
I also added some helpers for grabbing stuff like the key and value easily:
extension Item {
var value: Value? {
if case let .element(_, value) = self {
return value
}
return nil
}
}
We also need storage for the data in the dictionary:
private var storage: [Item] = Array(repeating: .empty, count: 8)
(8 is the initial size of the dictionary. In a real implementation, you might want to start with a bigger value, but for this example, smaller is easier to understand. We’ll implement resizing soon anyway.)
Next, we need to rewrite the get and set subscript methods. This looks a lot like the version of the dictionary from the last post:
subscript(key: Key) -> Value? {
get {
let index = abs(key.hashValue % storage.count)
return storage[index].value
}
set {
if let newValue = newValue {
let index = abs(key.hashValue % storage.count)
storage[index] = .element(key, newValue)
}
}
}
The abs ensures that negative values are handled correctly. This simple implementation makes our new test pass, but doesn’t handle collisions, so it’s time to write a test for that.
Handling Collision
We’d like to handle collisions, but we have a problem in setting up a test for them. As I mentioned earlier, Swift’s hashing is non-deterministic as of Swift 4.2, which means that if you run the same code twice, you’ll get two different hash values for the same object. That makes forcing a collision to happen really difficult.
We need a way to ensure that our test is perfectly reproducible and actually tests the thing we’re trying to test, which is a collision that has to occur every time we run this test. There two options here. First, you can set an environment variable called SWIFT_DETERMINISTIC_HASHING and find two values that happen to hash to the same bucket.
However, according to Karoy in the Swift forum thread announcing this new feature,
setting SWIFT_DETERMINISTIC_HASHING does not guarantee that hash values remain stable across different versions of the compiler/stdlib – please do not rely on specific hash values and do not save them across executions.
This means that we might have to update our tests every time the Swift toolchain is updated, and that’s not great. Instead, we can write a small type that can perfectly control what it hashes to. It needs fields for its underlying value and its hash value separately, so that a collision (two values that aren’t equal but have the same hash value) can be forced:
struct Hash: Hashable {
let value: String
let hashValue: Int
init(value: String, hashValue: Int) {
self.value = value
self.hashValue = hashValue
}
static func == (lhs: Hash, rhs: Hash) -> Bool {
return lhs.value == rhs.value
}
}
(This type has a warning telling us not to use hashValue directly. Nothing can really be done about that.) Given this small type, we can now write a test with a forced collision:
func testACollision() {
var dictionary = ProbingDictionary<Hash, String>()
dictionary[Hash(value: "a", hashValue: 1)] = "123"
dictionary[Hash(value: "b", hashValue: 1)] = "abc"
XCTAssertEqual(dictionary[Hash(value: "a", hashValue: 1)], "123")
XCTAssertEqual(dictionary[Hash(value: "b", hashValue: 1)], "abc")
}
The first and second items in the Dictionary have different values, but the same hash value, which will cause a collision. Running this test, we can observe the failure. The second item is overwriting the first. To fix this, we need to rewrite our get and set functions again.
Instead of returning the value at the hashed index, we need to check if it contains the right key. If it doesn’t, we need to step to the next value and check if it contains the right key. We keep doing this until we find the right key or hit an .empty element. Here’s an implementation that gets the job done.
get {
let index = abs(key.hashValue % storage.count)
return storage[index...]
.prefix(while: { !$0.isEmpty })
.first(where: { $0.key == key })?
.value
}
set {
if let newValue = newValue {
let index = abs(key.hashValue % storage.count)
if let insertionIndex = storage[index...].firstIndex(where: { $0.isEmpty || $0.key == key }) {
storage[insertionIndex % storage.count] = .element(key, newValue)
}
}
}
It can be nice to notice that while the prefix + first(where:) in the get and the firstIndex(where:) look different, they can actually be both written the same. By rewriting the get to use .first(where: { $0.isEmpty || $0.key == key }), you can make the two blocks look the same, which suggests that there might be some shared code we can extract from here. We’ll come back to that soon.
Collisions Near the Rollover Boundary
Now that our test is passing, time to write our next failing test. Careful readers will note that we’re not handling the rollover case correctly. If the probing happens at the boundary where the storage array rolls over it’ll return nil even though there is a value in the dictionary at that spot. Let’s write a test for that.
func testARolloverCollision() {
var dictionary = ProbingDictionary<Hash, String>()
dictionary[Hash(value: "a", hashValue: 7)] = "123"
dictionary[Hash(value: "b", hashValue: 7)] = "abc"
XCTAssertEqual(dictionary[Hash(value: "a", hashValue: 7)], "123")
XCTAssertEqual(dictionary[Hash(value: "b", hashValue: 7)], "abc")
}
We happen to know that our dictionary’s original size is 8, so we know to put the colliding elements at index 7 of the storage. However, to make this more robust, you might expose the size of the storage as an internal detail so your tests can rely on it but consumer code can’t. Either way, we have another failing test.
Fixing this one is kind of easy, but also kind of hard. Instead of just checking storage[index...], we need to follow it up with a check storage[..<index] as well. The naive solution for this is just to append the two together with a +.
let rotated = storage[index...] + storage[..<index]
This causes a major performance issue, which we have to address.
By examining the types, we can see what’s going on. rotated is an ArraySlice, which usually represents a view on an array — it stores the original array, a start index and an end index. However, this is not really one slice of an array, but rather two concatenated together, which means that because the internal storage of ArraySlice (the array and the two indices) can’t store the components of two different arrays, it will have to copy and modify one of them. Because ArraySlice is a copy-on-write type, this means that the whole storage array has to be copied into new storage when you execute that + operator. This has the ultimate effect of making every read from the dictionary be an O(n) operation, which is unacceptable. There are a few ways to fix this.
The apple/swift repo has a “Prototypes” folder which contains lots of interest and useful things that aren’t shipped with Swift or its standard library, but are useful nonetheless. Two of these are Concatenated and RotatedCollection. The first allows you to concatenate two collection together without copying, and the second enables you to “rotate” a collection around a pivot, which is exactly what we’re trying to do here. However, because we don’t have this type available to us, I’m going to take a different approach.
We discussed earlier that there’s a shared function we can extract from here, called firstOrEmptyIndex(matchingKey:), which finds the first index that matches our key or is empty. We can use that in both the get (grab the value of that Item, which return nil if it’s empty) and set (overwrite the key-value pair at that index). Let’s take a look at that function. We can add support for our new behavior here, checking all indices before the pivot as well.
func firstOrEmptyIndex(matchingKey key: Key) -> Int {
let block: (Item) -> Bool = { $0.isEmpty || $0.key == key }
let initialIndex = abs(key.hashValue % storage.count)
let index = storage[initialIndex...].firstIndex(where: block)
?? storage[..<initialIndex].firstIndex(where: block)
return index! % storage.count
}
Getting and setting become a lot simpler now:
subscript(key: Key) -> Value? {
get {
let index = firstOrEmptyIndex(forKey: key)
return storage[index].value
}
set {
if let newValue = newValue {
let insertionIndex = firstOrEmptyIndex(forKey: key)
storage[insertionIndex] = .element(key, newValue)
}
}
}
Tests are now passing. We can now handle rollover collisions.
At this point, I added a few more tests that didn’t require code changes. What if there’s a triple collision? What if there’s two or three objects in the dictionary that don’t collide? What about neighboring non-colliding objects? They all passed without requiring any code changes, so I’ll elide them here.
Resizing
The next feature I want to build is resizing. You might have noticed the force unwrap in that new function we just added. If none of our slots are .empty, we risk a crash. Resizing helps us ensure that there’s always free space in the dictionary. Again, test first! I think the best approach here is to store a large number of items in the dictionary (in this case 1000 items) and then assume that that’s enough items to force a resize.
func testResizing() {
let letters = "abcdefghijklmnopqrstuvwxyz"
func randomString() -> String {
return String((0...10).compactMap({ _ in letters.randomElement() }))
}
let values = (1...1000).map({ (randomString(), $0) })
var dictionary = ProbingDictionary<Hash, String>()
for (key, hash) in values {
dictionary[Hash(value: key, hashValue: hash)] = key
}
for (key, hash) in values {
XCTAssertEqual(dictionary[Hash(value: key, hashValue: hash)], key)
}
}
This test fails, so we know that it tests resizing correctly. Resizing is a pretty straightforward feature, and it’s very similar to how the resizing code in the previous blog post worked:
private mutating func resizeIfNeeded() {
guard self.storage.filter({ $0.hasElement }).count > storage.count / 2 else { return }
let originalStorage = self.storage
self.storage = Array(repeating: .empty, count: originalStorage.count * 2)
for case let .element(key, value) in originalStorage {
self[key] = value
}
}
Copy the storage, create a new storage that’s twice as big, and then copy all the elements into the new storage. I even got to use for case syntax in Swift, which I’ve never used before. If we call this method before trying to set any values, our new test will pass.
Collection Conformance
Let’s implement Collection conformance next. Instead of having a separate test for Collection stuff, we can just add an extra assert at the bottom of each test, asserting how many items should be in the Dictionary by the end of the test.
func testACollision() {
var dictionary = ProbingDictionary<Hash, String>()
dictionary[Hash(value: "a", hashValue: 1)] = "123"
dictionary[Hash(value: "b", hashValue: 1)] = "abc"
XCTAssertEqual(dictionary[Hash(value: "a", hashValue: 1)], "123")
XCTAssertEqual(dictionary[Hash(value: "b", hashValue: 1)], "abc")
XCTAssertEqual(dictionary.count, 2)
}
This is this simplest I could get the conformance to be, code-wise:
extension ProbingDictionary: Collection {
var startIndex: Int {
return storage.firstIndex(where: { $0.hasElement }) ?? storage.endIndex
}
var endIndex: Int {
return storage.endIndex
}
func index(after i: Int) -> Int {
return storage[i...].dropFirst().firstIndex(where: { $0.hasElement }) ?? endIndex
}
subscript(index: Int) -> (Key, Value) {
return (storage[index].key!, storage[index].value!)
}
}
While this works, it doesn’t quite meet the performance characteristics that Collection expects. startIndex should be an O(1) operation, but here it’s O(n), since it has to run through the storage array to find the first non-empty element. A better implementation would store the startIndex (and probably the current count, too) so that those things could be returned in O(1) time. The start index would store the first index in the storage array that is not .empty. Although it would add to the layout of the Dictionary, it’s probably worth it in order to deliver complexity guarantees that consumers would expect.
Now is also a fine time to throw in helpers for keys and values, which users also expect:
extension ProbingDictionary {
var keys: AnySequence<Key> {
return AnySequence(storage.lazy.compactMap({ $0.key }))
}
var values: AnySequence<Value> {
return AnySequence(storage.lazy.compactMap({ $0.value }))
}
}
Deletion
Okay. It’s time to write the code to handle deletion from the dictionary. I won’t lie to you — deletion with linear probing is hard. Think about it: you have to find the index (easy enough), replace it with .empty (fine), and then slide down every other element until the next .empty, unless the element is already in the lowest possible slot, in which case skip it and look for another one you can swap down (yikes!).
As always, test first:
func testDeletion() {
var dictionary = ProbingDictionary<Hash, String>()
dictionary[Hash(value: "a", hashValue: 7)] = "123"
dictionary[Hash(value: "b", hashValue: 4)] = "abc"
dictionary[Hash(value: "a", hashValue: 7)] = nil
XCTAssertEqual(dictionary[Hash(value: "a", hashValue: 7)], nil)
XCTAssertEqual(dictionary[Hash(value: "b", hashValue: 4)], "abc")
XCTAssertEqual(dictionary.count, 1)
}
(Adding collection conformance is quite nice here, since it lets us check that size of the dictionary is accurate after the deletion.)
Writing this code frankly sucked. There’s no cute code that could dig me out of this one:
var deletionIndex = firstOrEmptyIndex(forKey: key)
repeat {
let potentialNextIndex = (storage[deletionIndex...] + storage[..<deletionIndex])
.prefix(while: { !$0.isEmpty })
.dropFirst()
.firstIndex(where: { abs($0.key!.hashValue % storage.count) <= deletionIndex })
storage[deletionIndex] = .empty
if let nextIndex = potentialNextIndex {
let nextIndex = nextIndex % storage.count
storage[deletionIndex] = storage[nextIndex]
deletionIndex = nextIndex
}
} while !storage[deletionIndex].isEmpty
Truly the stuff of nightmares. Does it work? I think so. It’s hard to be confident when the algorithm is this complicated. At this point, I added tests to cover the cases I could think of — deletion with neighboring non-colliding elements, deletion with colliding elements, deletion with neighboring elements that both collide and don’t collide, deleting elements that don’t exist, deleting an element and writing back to that same key, and so on. I’m fairly confident at this point that the code works, but I much prefer code that I can understand by reading, rather than code whose working state depends on what failures I can think of and write tests for.
Tombstones
Fortunately, there is a better way to handle deletion. Right now, we only have two cases in our Item enum: either it has an element, or it doesn’t. But if we could add a little bit of information to that, we could make a distinction between slots that have never held an element, and slots that used to hold an element but don’t anymore. We call these tombstones (💀), since they represent a marker for something that lived once, but is now dead. Tombstones help us because when we are doing a set, we can treat tombstones the same as empty elements (because they are writable slots) but when doing a get, we can treat them as a filled slot that doesn’t match our key, so we always pass over them and continue. This simplifies things greatly.
Our “first or empty” function needs to change its signature a bit:
func firstOrEmptyIndex(forKey key: Key, includeTombstones: Bool = false) -> Int
Since we now make a distinction between .tombstone and .empty when reading and writing, each of those two operations will pass a different value for this Bool.
This makes our reading, writing, and deleting code super simple:
subscript(key: Key) -> Value? {
get {
let index = firstOrEmptyIndex(forKey: key)
return storage[index].value
}
set {
resizeIfNeeded()
if let newValue = newValue {
let insertionIndex = firstOrEmptyIndex(forKey: key, includeTombstones: true)
storage[insertionIndex] = .element(key, newValue)
} else {
let index = firstOrEmptyIndex(forKey: key)
if !storage[index].isEmpty {
storage[index] = .tombstone
}
}
}
}
I like simple, because I can understand simple. All the tests still pass, and thus we know our refactor was successful.
As an aside, I’d like to look at our original Item enum again:
enum Item {
case element(Key, Value)
case empty
}
When you first see this type, it can be tempting to try to replace it with (Key, Value)?, since this type holds the same amount of information as the optional tuple. However, not only does a custom enum provide more information to the reader of the code, it also is more easily extended to add the .tombstone case. With the optional tuple, it’s tough to see how the tombstone can be added. Using an enum makes it easy it add that extra case and get to the refactored state.
Linear probing is a super interesting approach for building dictionaries. Given that this post is nearly 3000 words, it’s not an easy technique, but as far as I know, it’s the gold standard for fast, reliable dictionaries. It’s used in Python, Rust, Swift, and many other languages besides. Understanding how it works is key to appreciating the speed and structure of a dictionary.
A few months ago, Aaron Patterson tweeted about some three-year-old uncommitted code:
tfw you work on a patch for 3 years and it’s like 2k lines and then you commit it and hope CI passes
Aaron’s CI build, naturally, didn’t pass.
At this point, Martin Fowler (the Martin Fowler, that Martin Fowler) chimed in:
is this where I get to be the annoying internet pedant and point out that if a patch has been developed for 3 years it’s most certainly not CI?
Why am I dredging up a twitter dunk from 3 months ago? Because this tweet, these 146 characters, have completely upended the way I think about branches, working in teams, and continuous integration in general.
Up until reading that tweet — a tweet! — almost all of the usage of the phrase “continuous integration” in my day-to-day life revolved around setting up some build server (usually but not always something like BitRise, BuddyBuild, Travis, etc) to build my code and run tests before I’m allowed to merge a branch.
But Martin’s tweet made me realize something. Build servers are just a tool used in the service of continuous integration. They don’t represent the philosophy behind it. The name carries the meaning quite well — continuously (as frequently as possible) integrate your work into some shared place, usually the mainline branch.
The implications are manifest. Integrating frequently means:
You don’t have to deal with horrible merges.
Not only do your teammates know what you’re working on at any given time, they can begin using it before you’re finished
If you have to drop your work for months (or, in Aaron’s case, years), the work you’ve done isn’t in limbo, doesn’t go out of date, and can be built on by the rest of your team.
Code review on shorter diffs is more fruitful than code review on longer diffs.
Code review earlier in the process can yield useful discussion on architecture and high-level patterns than code review later in the process, after the feature is fully built.
The fault lines between features form earlier, and any bugs that happen because of the interaction between two features emerge earlier, making them easier to solve and alleviating crunch time before a release — a problem that even the Swift compiler team has run into.
Code that isn’t integrated into your team’s mainline branch should be considered a liability at best, and dead at worst. Your job is to get the small, workable units of code merged in as early as possible.
A problem presents itself, however. You need to build a feature that takes 1,000 lines of code, but you’d like to merge it in in smaller chunks. How can you merge the code in if it’s not finished?
Broadly, the strategy is called “branch by abstraction”. You “branch” your codebase, not using git branches, but rather branches in the code itself. There’s no one way to do branch by abstraction, but many techniques that are all useful in different situations.
The easiest way to do this is to create functions and objects that aren’t actually called from anywhere. For example, making a new feature can involve writing the model objects first and making a PR from just those. Super easy to code review and get out of the way before the meat of your feature is ready.
Of course, the humble if statement is also a great way to apply this technique; use it liberally with feature flags to turn features on and off. (A feature flag doesn’t have to be complicated. A global constant boolean gets you pretty far. Feature flags don’t have to come from a remote source! However, I would recommend against compile-time #if statements, however. Code that doesn’t get compiled might as well be dead.)
Lastly, you can take advantage the language features you have access to. Get creative! I like to use Swift’s typealiases to enable old code to work while I rename a type or refactor some code. The Swift standard library uses this feature to great effect:
public typealias BidirectionalSlice<T> = Slice<T> where T : BidirectionalCollection
BidirectionalSlice used to be its own type, but with conditional conformance, a separate type wasn’t needed any more. However, in order for consumer code to continue compiling, a typealias was added to ease the transition between a world with this discrete type and a world without, all the while never breaking anyone’s code. If you’re interested, this whole file is full of such goodies.
If your team decides to take this approach, then you’re going to have a lot more code reviews in front of you. If there’s a lot of latency in your pull request pipeline, then that latency will begin to block you and your teammates’ efforts to continuously integrate their changes into the mainline branch.
It’s important to remember that code review is a blocked thread of execution, and, as a reviewer, your job is to unblock your teammates as quickly as possible. Prioritizing code review over almost all other work alleviates the slow code review pipeline, and enables steady integration of your coworkers’s code.
Ultimately, continuous integration isn’t a build server, it’s a mindset. Keep your outstanding branches small and get code into the mainline branch steadily and frequently, and your team will see appreciable yields.
Just a heads up — this blog post has nothing to do with the coordinator pattern.
Those that have been following my blog for a long time might remember an old post, Cache Me If You Can. The idea behind the post was simple: if you just want caching, eschew Core Data in favor of something simple: a file on disk that represents a single NSCoding object. Multiple types of things you want to store? Multiple files on disk.
That concept found its way into the Backchannel SDK, as BAKCache, and has sort of followed me around ever since. It found its way into Swift, learned what a generic was, got renamed ObjectStorage, figured out how to handle user data as well as caches, and now supports Codable instead of NSCoding. You can find that version in this gist.
Recently, I’d found myself reading the object, mutating it, and then writing it back. Once I wrote that code a few times, I started noticing a pattern, and decided to formalize it in a method on the class:
func mutatingObject(defaultValue: T, _ block: @escaping (inout T) -> Void) {
var object = self.fetchObject() ?? defaultValue
block(&object)
self.save(object: object)
}
However, there’s a problem revealed by this method. The class’s design encourages you to create lots of instances of ObjectStorage wherever you need them, and thus allows you to read and write to the same file from lots of different places. What happens when two instances read at the same time, both mutate the object in question, and try to write it back to the file? Even if the read and write were individually perfectly atomic, the second instance to write would overwrite the mutation from the first!
Access to the file needs to be gated somehow, and if one object is in the process of mutating, no other object should be allowed to read until that mutation is complete.
Foundation provides a handy API for this, called NSFileCoordinator, which, along with a protocol called NSFilePresenter, ensures that any time a file is updated on the disk, the NSFilePresenter object can be notified about it, and update itself accordingly. This coordination works across processes, which is impressive, and is what enables features like Xcode prompting you to reopen the Xcode project when there’s a change from a git reset or similar.
NSFileCoordinator is indispensable in a few cases:
Since Mac apps deal with files being edited by multiple apps at once, almost all document-based Mac apps use it. It provides the underpinning for
NSDocument.Extensions on iOS and the Mac are run in different process and may be mutating the same files at the same time.
Syncing with cloud services requires the ability to handle updates to files while they are open, as well as special dispensation for reading files for the purpose of uploading them.
For our use case, we don’t really fall into any of the buckets where NSFileCoordinator is crucial — our files are all in our sandbox so no one else is allowed to touch them, and we don’t have an extension. However, NSFileCoordinator can help with file access coordination within the same process as well, so it can potentially solve our problem.
The documentation for NSFileCoordinator and NSFilePresenter are sadly not great. Here’s the gist: NSFilePresenter is the protocol through which the system informs you about what changes are about to happen to your file and how to react to them. NSFileCoordinator, on the other hand, does two things: first, it “coordinates” access to files at URLs, ensuring that two chunks of code don’t modify the data at some URL at the same time; second, it informs any active presenters (across processes!) about upcoming changes to files. We don’t care much about the latter, but the former is relevant to our work here.
Let’s add coordination to the save(object:) method.
func save(object: T) {
You need to keep track of a mutable error, which reports if another file presenter caused an error while it was trying to prepare for the execution of the block.
var error: NSError?
Next, you create a file coordinator specific to the operation. You can also pass the NSFilePresenter responsible for this change to the NSFileCoordinator. As far as I can tell, this is only used to exclude the current file presenter from getting updates about the file. Since we don’t need any of the file presenter callbacks, we can just pass nil for this parameter and not worry about it.
let coordinator = NSFileCoordinator(filePresenter: nil)
This next line includes a lot of detail. Let’s take a look first and then break it down.
coordinator.coordinate(writingItemAt: storageURL, options: .forReplacing, error: &error, byAccessor: { url in
The method is passed the URL we care about, as well as our mutable error.
The block returns to you a URL that you can use. It asks you to use this URL, since it might not be the same as the URL you pass in.The reading and writing options are very important. They are the biggest determinant of what URL you’ll get in your block. If you pass something like .forUploading as a reading option, it’ll copy the file to a new place (no doubt using APFS’s copy-on-write feature), and point you to that new location so that you can perform your lengthy upload without blocking any other access to the file.
With that heavy line of code past us, the actual content of the block stays largely the same as before:
do {
let data = try Data(contentsOf: url)
let decoder = JSONDecoder()
result = try decoder.decode(T.self, from: data)
} catch {
if (error as NSError).code != NSFileReadNoSuchFileError {
print("Error reading the object: \(error)")
}
}
I replicated the same pattern across the fetch, mutate, and delete functions as well. You can see that version of the code here.
To test, for example, the mutatingObject code, I hit the file with 10,000 accesses, each incrementing an integer in the stored file by 1. I’ll leave out the cruft of the test, but the bulk of it looked like this:
let limit = 10_000
DispatchQueue.concurrentPerform(iterations: limit, execute: { i in
objectStorage.mutatingObject(defaultValue: IntHolder(value: 0), { holder in
holder.value += 1
})
})
XCTAssertEqual(objectStorage.fetchObject()?.value, limit)
This is where I discovered my problem. Without using NSFileCoordinator, the mutatingObject dropped about 70% of writes. With it, even using the reading and writing options correctly, I was still losing a few dozen writes every 10,000. This was a serious issue. An object storage that loses about half a percent of writes still isn’t reliable enough to use in production. (Apple folks, here’s a radar. It includes a test project with a failing test.)
At this point, I started thinking about what I was actually trying to do, and whether NSFileCoordinator was really the right API for the job.
The primary use cases for NSFileCoordinator are dealing with document-like files that can change out from underneath you from other processes, and syncing data to iCloud, where data might change out from underneath you from iCloud. Neither of these are really issues that I have, I just need to coordinate writes in a single process to ensure that no data races occur. The fundamental abstraction of “coordinating” reads and writes is sound, I don’t happen to need most of the complexity of NSFileCoordinator.
I started thinking about how NSFileCoordinator had to be structured under the hood to act the way it does. It must have some kind of locking mechanism around each URL. Reads can be concurrent and writes have to be serial. Other than that, I don’t need much.
Based on that, I built my own simple file coordinator. It keeps track of a global mapping of URLs to dispatch queues.
final class FileCoordinator {
private static var queues: [URL: DispatchQueue] = [:]
To make ensure that access of the global queues variable is thread-safe, I need a queue to access the queues. (I heard you like queues.)
private static let queueAccessQueue = DispatchQueue(label: "queueAccessQueue")
From there, we need to get a queue for any URL. If the queue doesn’t exist yet in the queue map yet, we can make one and stick it in.
private func queue(for url: URL) -> DispatchQueue {
return FileCoordinator.queueAccessQueue.sync { () -> DispatchQueue in
if let queue = FileCoordinator.queues[url] { return queue }
let queue = DispatchQueue(label: "queue-for-\(url)", attributes: .concurrent)
FileCoordinator.queues[url] = queue
return queue
}
}
Lastly, we can implement our public interface, and use the reader-writer pattern to ensure that data is accessed safely.
func coordinateReading<T>(at url: URL, _ block: (URL) throws -> T) rethrows -> T {
return try queue(for: url).sync {
return try block(url)
}
}
func coordinateWriting(at url: URL, _ block: (URL) throws -> Void) rethrows {
try queue(for: url).sync(flags: .barrier) {
try block(url)
}
}
}
There are a few benefits of this over Foundation’s NSFileCoordinator. First, it doesn’t drop any writes. I can hammer on this implementation and it safely updates the file on each iteration. Second, I control it. I can change it if I run into any issues, and it has clear room to grow. Lastly, it takes advantage of some great Swift features, like rethrows and using generics to return an object from the inner block and have it be returned from the outer method call.
There are downsides to this approach, too. It naturally won’t work across processes like Apple’s version can, and it won’t have a lot of the optimizations for the different reading and writing options (even though we could add them).
There’s also lots of room to grow here. For example, if you’re touching a lot of URLs, your queues dictionary would grow boundlessly. There are a few approaches to add a limit to that, but I don’t expect it to touch more than 10 or so URLs, so I think it’s fine without the added complexity for now.
Replacing a system class can be a tough call — Apple’s classes tend to be well-written and handle lots of edge cases gracefully. However, when you find that their implementations aren’t serving you, it can be worth it to examine how complicated replacing it will be. In this case, replacing it wasn’t too much code, my test harness could catch bugs, and not relying on already-written code reduced the complexity rather than increasing it.
Update: An engineer at Apple responded to my Radar. It was a configuration error on my part:
The problem here is that the code is using an (apparently useless) NSFilePresenter when initializing the NSFileCoordinator. File Coordination will actually NOT block again other read/write claims made with the same NSFileCoordinator instance or NSFileCoordinator instances made with the same filePresenter or purposeIdentifier.
You most likely just want to use the default initializer for NSFileCoordinator here, or else manually queue up writes internally.
They continued:
Note: if you don’t care about other processes or in-process code outside of your control (i.e. in a framework), you absolutely should NOT use file coordination as a means of mutual exclusion. The cross-process functionality is definitely the main motivation to use File Coordination, but it comes with a relatively high performance (and cognitive) cost in comparison to in-process means.
Given that my in-process FileCoordinator works well, and the Apple engineer so strenously recommended that I don’t use NSFileCoordinator, I’ll probably just keep using the class I made.
In Dave Abraham’s WWDC talk, Embracing Algorithms, he talks about finding common algorithms and extracting them into the generic (and testable) functions. One thing in this vein that I like to look for is a few collection operations that cluster together that can be combined into a single operation. Often times, when combining these operations, you’ll also find a beneficial optimization that can be drawn out.
The first example of this is a method added in Swift 3:
// when you see:
myArray.filter({ /* some test */ }).first
// you should change it to:
myArray.first(where: { /* some test */ })
The predicate block stays exactly the same and the result is the same, but it’s shorter, more semantic, and more performant, since it’s not allocating a new array and finding every single object in the array that passes the test — just the first.
Another example is the count(where:) function that I helped add to Swift 5:
// when you see:
myArray.filter({ /* some test */ }).count
// you should change it to:
myArray.count(where: { /* some test */ })
Again: shorter, more semantic, and more performant. No arrays allocated, no extra work done.
In a particular project of ours, we had one common pattern where we would do a sort followed by a prefix. This code, for example, needed to find the 20 most recently created images.
return images
.sorted(by: { $0.createdAt > $1.createdAt })
.prefix(20)
You could also imagine something like a leaderboard, where you want the top 5 users with the highest scores.
I stared at this code until my eyes began to bleed. Something was fishy about it. I started thinking about the time complexity. If you think of the length of the original array as n, and the number of items you want to end up with as m, you can start to analyze the code. The sort is O(nlogn), and prefixing is a very cheap operation, O(1). (Prefixing can be as slow as O(m), but arrays, which are what we are dealing with here, are random access collections and can prefix in constant time.)
Here’s what was bugging me: Getting the single smallest element of a sequence (using min()) requires only a single pass over the all of its contents, or O(n). Getting all of the elements ordered by size is a full sort, or O(nlogn). Getting some number m of them where m is smaller than n should be somewhere in between, and if m is much, much smaller than n, it should be even closer to O(n).
In our case, there are lots of images (n is about 55,000) and the amount we’re actually interested in small (m is 20). There should be something to optimize here. Can we optimize sorting such that will only sort the first m elements?
It turns out that, yes, we can do something along those lines. I call this function smallest(_:by:). It takes both the parameters of the sort and the prefix, which are the number m and the comparator to sort with:
func smallest(_ m: Int, by areInIncreasingOrder: (Element, Element) -> Bool) -> [Element] {
Starting with the first m elements pre-sorted (this should be quick, since m should be much smaller than the length of the sequence):
var result = self.prefix(m).sorted(by: areInIncreasingOrder)
We loop over all the remaining elements:
for element in self.dropFirst(m) {
For each element, we need to find the index of the first item that’s larger than it. Given our areInIncreasingOrder function, we can do this by passing the element first, and each element of result second.
if let insertionIndex = result.index(where: { areInIncreasingOrder(element, $0) }) {
If an index is found, that means that there’s a value bigger than element in our result array, and if we insert our new value at that value’s index, it’ll be correctly sorted:
result.insert(element, at: insertionIndex)
And remove the last element (which is now out of bounds of our number m):
result.removeLast()
If the index wasn’t found, we can ignore the value. Lastly, once the for loop is done, we can return the result:
}
}
return result
}
The whole function looks like this:
extension Sequence {
func smallest(_ m: Int, by areInIncreasingOrder: (Element, Element) -> Bool) -> [Element] {
var result = self.prefix(m).sorted(by: areInIncreasingOrder)
for e in self.dropFirst(n) {
if let insertionIndex = result.index(where: { areInIncreasingOrder(e, $0) }) {
result.insert(e, at: insertionIndex)
result.removeLast()
}
}
return result
}
}
If this is reminding of you of your early coursework in computer science classes, that’s good! This algorithm is something like a selection sort. (They aren’t exactly the same, because this pre-sorts some amount, and selection sort is a mutating algorithm and this isn’t.)
The time complexity of this is a bit tougher to analyze, but we can do it. The sort of the initial bit is O(mlogm). The big outer loop is O(n), and each time it loops, it calls index(where:) (O(m)) and insert(_:at:) (O(m) as well). (Insertion is O(m) because it potentially has to slide all the elements down to make space for the new element.) Therefore, the time complexity of this is O(mlogm + n * (m + m)), or O(mlogm + 2nm). Constants fall out, leaving us with O(mlogm + nm).
If m is much, much smaller than n, the m terms become more or less constant, and you end up with O(n). That’s a good improvement over our original O(nlogn)! For our original numbers of 55,000 images, that’s should be a roughly five-fold improvement.
This function that we’ve written is broadly an optimization over prefix + sort, but there are two smaller optimizations that I want to discuss here as well.
There’s one pretty low hanging fruit optimization here. We’re looking for the smallest 20 items in an array of 55,000 elements. Most (almost all!) of the elements we check are not going to be needed for our result array. If we throw in one check to see if the element we’re looking at is larger than the last element in the result array, and if it is, just skip it entirely. There’s no sense searching through the array for its insertion index if the element is larger than the last element of result.
if let last = result.last, areInIncreasingOrder(last, e) { continue }
Testing with this check enabled caused a 99.5% drop in linear searches through the result array, and the whole algorithm increased roughly 10x in speed. I want to credit to Greg Titus for pointing this optimization out to me — I would have missed it entirely.
If you want to go take another step, you can do one more (slightly harder to implement) optimization. This one relies on two facts. First, we’re using index(where:) to find the insertion in the result array; second, the result is always sorted. index(where:) is a linear operation by default, but if we’re searching through an already-sorted list, it can be tempting try and replace the linear search with a binary search. I took a crack at this.
To understand how these optimizations affected the performance of the algorithm, Nate Cook helped me become familiar with Karoy Lorentey’s Attabench tool, benchmarking each of these solutions. Because all of our complexity analysis until this point was theoretical, until we actually profile the code we’re concerned with (and ideally on the devices in question), any conclusions are just educated guesses. For example, sort generally is O(nlogn), but different algorithms handle different kinds of data differently. For example, already sorted data might be slower or faster to sort for a particular algorithm.
Attabench showed me a few things.
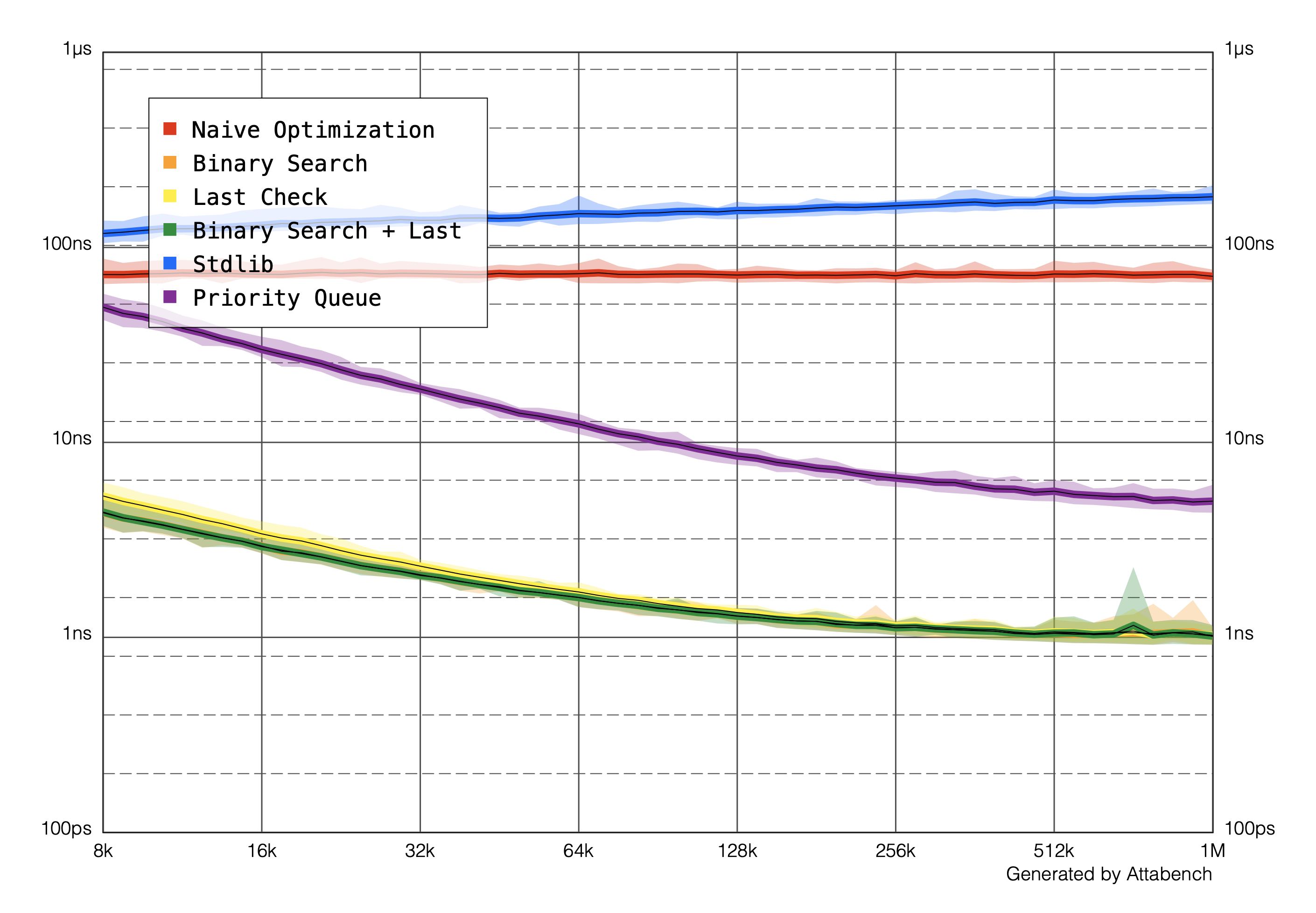
(I also threw in a priority queue/heap solution written by Tim Vermuelen, since a few people asked for how that compares.)
First, my guess that searching through the array a single time was faster than fully sorting the array was correct. Especially as the sequence in question gets long, sorting gets worse but our “naive optimization” stays constant. (The Y axis represents the time spent per item, rather than total, meaning that O(n) algorithms should be a flat line.)
Second, the “last check” and the binary search optimizations have almost exactly the same performance characteristics when they are on their own (you can’t actually see the orange and yellow lines because they’re behind the green), as when they’re used together. However, because binary search is hard to write and even harder to get right, you may decide it isn’t worth it to add.
The takeaway here for me is that profiling and optimizing is hard. While complexity analysis can seem a bit academic — “When am I going to use this in my real career?” one asks — understanding the time and space complexity of your algorithms can help you decide which directions to explore. In this case, understanding the time complexity of sorting led us towards a broad idea which bore fruit. Finally, benchmarking and profiling with a wide variety of data leads to the most accurate information about how your code will work in production.
And also, next time you see a sort followed by a prefix, think about replacing it with smallest(_: by:).
Foundation’s URL loading is robust. iOS 7 brought the new URLSession architecture, making it even more robust. However, one thing that it’s never been able to do natively is multipart file uploads.
What is a multipart request?
Multipart encoding is the de facto way of sending large files over the internet. When you select a file as part of a form in a browser, that file is uploaded via a multipart request.
A multipart request mostly looks like a normal request, but it specifies a unique encoding for the HTTP request’s body. Unlike JSON encoding ({ "key": "value" }) or URL string encoding (key=value), multipart encoding does something a little bit different. Because of the body of a request is just a long stream of bytes, the entity parsing the data on the other side needs to be able to determine when one part ends and another begins. Multipart requests solve this problem using a concept of “boundaries”. In the Content-Type header of the request, you define a boundary:
Accept: application/json
Content-Type: multipart/form-data; boundary=khanlou.comNczcJGcxe
The exact content of the boundary is not important, it just needs to be a series of bytes that is not present in the rest of the body (so that it can meaningfully act as a boundary). You can use a UUID if you like.
Each part can be data (say, an image) or metadata (usually text, associated with a name, to form a key-value pair). If it’s an image, it looks something like this:
--<boundary>
Content-Disposition: form-data; name=<name>; filename=<filename.jpg>
Content-Type: image/jpeg
<image data>
And if it’s simple text:
--<boundary>
Content-Disposition: form-data; name=<name>
Content-Type: text/plain
<some text>
After the last part in the request, there’s one more boundary, which includes an extra two hyphens, --<boundary>--. (Also, note that the new lines all have to be CRLF.)
That’s pretty much it. It’s not a particularly complicated spec. In fact, when I was writing my first client-side implementation of multipart encoding, I was a bit scared to read the RFC for multipart/form-data. Once I took a look at it, however, I understood the protocol a lot better. It’s surprisingly readable, and nice to go straight to the source for stuff like this.
That first implementation was in the Backchannel SDK, which is still open source. You can see the BAKUploadAttachmentRequest and the BAKMultipartRequestBuilder, which combine to perform the bulk of the multipart handling code. This particular implementation only handles a single file and no metadata, but it serves as an example of how this request can be constructed. You could modify it to support metadata or multiple files by adding extra “parts”.
However, if you want to upload multiple files, whether your service expects one request with many files or many requests with one file each, you’ll soon run into a problem. If you try to upload too many files at once, your app will crash. Because this version of the code loads the data that will be uploaded into memory, a few dozen full-size images can crash even the most modern phones.
Streaming files off the disk
The typical solution to this is to “stream” the files off the disk. The idea is that the bytes for any given file stay on the disk, until the moment they’re needed, at which point they’re read off the disk and sent straight to the network machinery. Only a small amount of the bytes for the images is in memory at any given time.
I came up with two broad approaches to solving this problem. First, I could write the entire data for the multipart request body to a new file on disk, and use an API like URLSession’s uploadTask(with request: URLRequest, fromFile fileURL: URL) to stream that file to the API. This would work, but it seemed like it should be possible to accomplish this without writing a new file to the disk for each request. There would also be a bit of cleanup to handle after the request has been sent.
The second approach is to build a way to mix data in memory with data on the disk, and present an interface to the network loading architecture that looks like a chunk of data from a single source, rather than many.
If you’re thinking this sounds like a case for class clusters, you’re dead on. Many common Cocoa classes allow you to make a subclass that can act as the super class by implementing a few “primitive” methods. Think -count and -objectAtIndex: on NSArray. Since every other method on NSArray is implemented in terms of those two, you can write optimized NSArray subclasses very easily.
You can create an NSData that doesn’t actually read any data off the disk, but rather creates a pointer directly to the data on disk, so that it never has to load the data into memory to read it. This is called memory mapping, and it’s built on a Unix function called mmap. You can use this feature of NSData by using the .mappedIfSafe or .alwaysMapped reading options. And NSData is a class cluster, so if we could make a ConcatenatedData subclass (that works like FlattenCollection in Swift) that allows you treat many NSData objects as one continuous NSData, we would have everything we need to solve this problem.
However, when we look at the primitive methods of NSData, we see that they are -count and -bytes. -count isn’t a big deal, since we can easily sum up the counts of all the child datas; -bytes, however, poses a problem. -bytes should return a pointer to a single continuous buffer, which we won’t have.
To handle discontinuous data, Foundation gives us NSInputStream. Fortunately, NSInputStream is also a class cluster. We can create a subclass that makes many streams look like one. And with APIs like +inputStreamWithData: and +inputStreamWithURL:, we can easily create input streams that represent the files on the disk and the data in memory (such as our boundaries).
If you look at the major third-party networking libraries, you’ll see that this is how AFNetworking actually works. (Alamofire, the Swift version of AFNetworking, loads everything into memory but writes it to a file on disk if it is too big.)
Putting all the pieces together
You can see my implementation of a serial InputStream here in Objective-C and here in Swift.
Once you have something like SKSerialInputStream, you can combine streams together. Given a way to make the prefix and postfix data for a single part:
extension MultipartComponent {
var prefixData: Data {
let string = """
\(self.boundary)
Content-Disposition: form-data; name="\(self.name); filename="\(self.filename)"
"""
return string.data(using: .utf8)
}
var postfixData: Data {
return "\r\n".data(using: .utf8)
}
}
You can compose the metadata for the upload and the dataStream for the file to upload together into one big stream.
extension MultipartComponent {
var inputStream: NSInputStream {
let streams = [
NSInputStream(data: prefixData),
self.fileDataStream,
NSInputStream(data: postfixData),
]
return SKSerialInputStream(inputStreams: streams)
}
}
Once you can create an input stream for each part, you can join them all together to make an input stream for the whole request, with one extra boundary at the end to signal the end of the request:
extension RequestBuilder {
var bodyInputStream: NSInputStream {
let stream = parts
.map({ $0.inputStream })
+ [NSInputStream(data: "--\(self.boundary)--".data(using: .utf8))]
return SKSerialInputStream(inputStreams: streams)
}
}
Finally, assigning that to the httpBodyStream of your URL request completes the process:
let urlRequest = URLRequest(url: url)
urlRequest.httpBodyStream = requestBuilder.bodyInputStream;
The httpBodyStream and httpBody fields are exclusive — only one can be set. Setting the input stream invalidates the Data version and vice versa.
The key to streaming file uploads is being able to compose many disparate input streams into one. Something like SKSerialInputStream makes the process a lot more manageable. Even though subclassing NSInputStream can be a bit perilous, as we’ll see, once it’s solved the solution to the problem falls out more or less naturally.
Subclassing notes
The actual process of subclassing NSInputStream wasn’t fun. Broadly put, subclassing NSInputStream is hard. You have to implement 9 methods, 7 of which can have trivial default implementations that the superclass should handle. The documentation only mentions 3 of the 9 methods, and you have to dig to find out that you have to implement 6 more methods from NSStream (the superclass of NSInputStream) including two run loop methods where empty implementations are valid. There also used to be 3 private methods that you had to implement, though they don’t seem to be a concern any longer. Once you’ve implemented these methods, you also have to support several readonly properties as well: streamStatus, streamError, and delegate need to be defined.
Once you get all the details about subclassing right, you get to the challenge of providing an NSInputStream that behaves in a way that other consumers would expect. The state of this class is heavily coupled in non-obvious ways.
There are a few pieces of state, and they all need to act in concert at all times. For example, hasBytesAvailable is defined separately from the other state, but there are still subtle interactions. I found a late-breaking bug where my serial stream would ideally return self.currentIndex != self.inputStreams.count for hasBytesAvailable, but that caused a bug where the stream stayed open forever and would cause a timeout for the request. I patched over this bug by always returning YES, but I never figured out the root of it.
Another piece of state, streamStatus, has many possible values, but the only ones that seem to matter are NSStreamStatusOpen and NSStreamStatusClosed.
The final interesting piece of state is the byte count, returned from the read method. In addition to returning a positive integer for the byte count, a stream can return a byte count of -1, which indicates an error, which then has to be checked by via the streamError property, which must no longer be nil. It can also return a byte count of 0, which, according to the documentation, is another way that to indicate that the end of the stream has been reached.
The documentation doesn’t guide you what combinations of states are valid. If my stream has a streamError, but the status is NSStreamStatusClosed rather than NSStreamStatusError, will that cause a problem? Managing all this state is harder than it needs to be, but it can be done.
I’m still not fully confident that SKSerialStream behaves perfectly in all situations, but it seems to support uploading multipart data via URLSession well. If you use this code and find any issues, please reach out and we can make the class better for everyone.
Update, August 2019: One final note I want to add on this code. I was seeing some small bugs with it, and I spent a few nights debugging. This was pretty painful, so I want to leave this note for readers and of course, future versions of myself. If you give you URLRequest a Content-Length, NSURLSession will use that to determine exactly how many bytes to pull out of your input stream. If the content length is too low, it will truncate your stream precisely at that byte. If the content length is too high, your request will timeout as it waits for bytes that will never come because the stream is exhausted. This, sadly, is not documented anywhere.
Swift 4.2 brings some new changes to how hashing works in Swift. Previously, hashing was fully delegated to the object itself. You would ask an object for its hashValue, and it would respond with the fully cooked integer representing the hash. Now, objects that conform to Hashable describe how to combine their constituent components into a Hasher object that’s passed in as a parameter. This is great for a few reasons.
Good hashing algorithms are hard to write. End users of Swift shouldn’t be responsible for knowing the best way to combine their constituent components into a good hash value.
Hash values should be different for each execution of the program, to discourage users from storing them in any way and for security reasons. Descriptive hashing allows the seeds of the hashing function to change each time you run the program.
It makes more interesting data structures possible, which is what we’re going to focus on in this post.
I’ve written here before about how to use Swift’s Hashable protocol to write a Dictionary from scratch (and it will help to read that post before this one, but isn’t necessary). Today, I want to talk about a different kind of data structure, one that’s probabilistic rather than definite: the Bloom filter. As we build it, we’ll use a few new features in Swift 4.2, including the new hashing model.
Bloom filters are weird. Imagine a data structure where:
you can insert values into it
you can query it to see if a value is contained in it
it can use a tiny amount of storage to a store a huge amount of objects
but:
you can’t enumerate the objects in it
it sometimes has false positives (but never false negatives)
you can’t remove values from them
When would you want something like this? Medium uses them to keep track of the read status of posts. Bing uses them for search indexes. You could use them to build a cache for if a username is valid (in an @-mention, for example) without having to hit the database. They’re particularly useful on the server, where you could have immense scale but not necessarily immense resources.
(If you’ve ever done any graphics work, you might be wondering how this relates to the other bloom filter. The answer is, it doesn’t. That bloom filter is a lowercase b bloom, like a flower. This one is named after a person named Bloom. Total coincidence.)
How do they work?
Putting an object into a Bloom filter is sort of like putting it into a set or a dictionary: you need to calculate a hash value for the object and mod the hash value by the size of your storage array. At that point, instead of storing the value at that position in the index (like you would with a set or a dictionary), you simply flip a bit at that index: change a value from false to true.
Let’s take a simple example to understand how the filter works, and then we’ll crank it up to make it web scale. Imagine a boolean array (sometimes called a bit array) of 8 false values:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
---------------------------------
| | | | | | | | |
This represents our Bloom filter. I’d like to insert the string “soroush” into it. The string hashes to 9192644045266971309, which, when modded by 8, yields 5. I’ll flip the bit at that index.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
---------------------------------
| | | | | | * | | |
Next, I’d like to insert the string, “swift”. It yields a hash of 7052914221234348788, which we then mod by 8: flip the bit at index 4.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
---------------------------------
| | | | | * | * | | |
To test if the Bloom filter contains the string “soroush”, I hash and mod again, yielding 5 again, which is set to true. “soroush” is indeed in the Bloom filter.
You can’t just test the cases where your thing works though, so let’s write some negative tests. Testing the string “khanlou” yields an index of 2, so we know it’s not in the bloom filter. So far, so good. Next test: the string “hashable” yields an index of 5, which…causes a collision! It returns true even though the value was never inserted into the Bloom filter. This is an example of a Bloom filter giving you a false positive.
Since we want to minimize these false positives, there are two main strategies we can use. First, and the more interesting of the two: instead of hashing the value once, we can hash it twice, or three times, with different hashing functions. As long as they are all well-behaved hashing functions (evenly distributed, consistent, minimal collisions), we can generate multiple indices to flip for each value. Now, when we hash “soroush”, we do it twice, and generate two indices, and flip the bools there. But now, when we go to check if “khanlou” is included in the Bloom filter, one of its hashes will collide with one of the hashes for “soroush”, but the chance that both of its hashes will collide has become smaller. You can scale this number up. I’ll use the 3 hashes in the code below, but you could use more.
Of course, if you use more hashes, each element will take up more space in the bit array. However, we’re using practically nothing right now. Our data array is 8 booleans (or bits) which is 1 byte. This is second tactic for minimizing false positives: scale the bit array up. We can make it pretty big before we even start noticing it. We’ll use a default of 512 bits for the code example below.
Now, even using both of these strategies, you’ll still get collisions, and thus false positives, but you’ll get fewer of them. This is one of the downsides of using Bloom filters, but in the right circumstances, the speed and space savings are a worthwhile tradeoff.
I want to touch on three other things to note before we get into code. First, you can’t resize a Bloom filter. When you mod the hash value, you’re destroying information, and you can’t get that information back unless you keep the original hashes around — defeating the dramatic space savings you can get with this data structure.
Secondly, you can see how it would be impossible to enumerate the elements in a Bloom filter. You don’t have them anymore, just some of their artifacts (in the form of hashes).
Lastly, you can also see how you can’t remove elements from a Bloom filter. If you try to flip the bits back to false, you don’t know who had originally flipped them to true. The value you’re trying to remove, or a different value? You’d start causing false negatives as well as false positives. (This may actually be a worthwhile tradeoff for you!) You could get around this by keeping a count at each index instead of a boolean, which would also have storage implications, but again, could be worthwhile depending on your use case.
So, let’s get to some code. There are some choices that I’ll make here that you might choose to make differently, starting with whether or not to make the object generic. I think it makes sense to have the object have a little more metadata about what it’s supposed to be storing, but if you find that too restrictive, you can change it.
struct BloomFilter<Element: Hashable> {
// ...
}
We need to store two main things in this type. First, data, which represents our bit array. This will store all the flags that correspond to the hashes:
private var data: [Bool]
Next, we need our different hash functions. Some Bloom filters use actually different methods of computing the hash, but I think it’s easier to use the same algorithm, but mix in one additional randomly generated value.
private let seeds: [Int]
When setting up the Bloom filter, we need to set up both instance variables. Our bit array is going to simply repeat the false value, and our seeds will use Swift 4.2’s new Int.random API to generate the seeds we need.
init(size: Int, hashCount: Int) {
data = Array(repeating: false, count: size)
seeds = (0..<hashCount).map({ _ in Int.random(in: 0..<Int.max) })
}
I also included a convenience initializer with some nice defaults.
init() {
self.init(size: 512, hashCount: 3)
}
There are two main functions we need to write: insert and contains. They both need to take the element and calculate one hash value for each of the seeds. Great fodder for a private helper function. We need to create one hash value for each seed, because our seed values represent the “different” hashing functions.
private func hashes(for element: Element) -> [Int] {
return seeds.map({ seed -> Int in
// ...
})
}
To write the body of this function, we need to create a Hasher (new in Swift 4.2), and pass in the object we want to hash. Mixing in the seed as well ensures that the hashes won’t collide.
private func hashes(for element: Element) -> [Int] {
return seeds.map({ seed -> Int in
var hasher = Hasher()
hasher.combine(element)
hasher.combine(seed)
let hashValue = abs(hasher.finalize())
return hashValue
})
}
Also, note the absolute value on the hash value. Hashes can come back as negative, which will crash our array access later. This removes one bit of entropy, which is probably fine.
Ideally, you’d be able to initialize the Hasher with a seed, instead of mixing it in. Swift’s Hasher uses a different seed for each launch of the application (unless you set an environment variable which they added for consistent hashing between launch, mostly for testing purposes), meaning you can’t write these values to disk. If we controlled the seed of the Hasher, then we could write these values to disk as well. As this Bloom filter currently stands, it should only be used for in-memory caches.
The hashes(for:) function does a lot of the heavy lifting, and makes our insert method very straightforward:
mutating func insert(_ element: Element) {
hashes(for: element)
.forEach({ hash in
data[hash % data.count] = true
})
}
Generate all the hashes, mod each one by the length of the data array, and set the bit at that index to true.
contains is likewise simple, and gives us a chance to use another new Swift 4.2 feature, allSatisfy. This new function tells you if all of the objects in the sequence pass some test, represented by a block:
func contains(_ element: Element) -> Bool {
return hashes(for: element)
.allSatisfy({ hash in
data[hash % data.count]
})
}
Because the result of data[hash % size] is already a boolean, it fits quite nicely into allSatisfy.
You can also add an isEmpty method that checks if all of the values in the data are false.
Bloom filters are one of the weirder data structures. Most of the data structures we deal with are deterministic. When you put an object in a dictionary, you know it’ll be there later. Bloom filters, on the other hand, are probabilistic, sacrificing certainty for space and speed. Bloom filters aren’t something that you’ll use every day, but when you do need them, you’ll be happy to know they exist.
Back in the days before Crusty taught us “protocol-oriented programming”, sharing of implementations happened mostly via inheritance. In an average day of UIKit programming, you might subclass UIView, add some child views, override -layoutSubviews, and repeat. Maybe you’ll override -drawRect. But on weird days, when you need to do weird things, you start to look at those other methods on UIView that you can override.
One of the more eccentric corners of UIKit is the touch handling subsystem. This primarily includes the two methods -pointInside:withEvent: and -hitTest:withEvent:.
-pointInside: tells the caller if a given point is inside a given view. -hitTest: uses -pointInside: to tell the caller which subview (if any) would be the receiver for a touch at a given point. It’s this latter method that I’m interested in today.
Apple gives you barely enough documentation to figure out how to reimplement this method. Until you learn to reimplement it, you can’t change how it works. Let’s check out the documentation and try to write the function.
override func hitTest(_ point: CGPoint, with event: UIEvent?) -> UIView? {
// ...
}
First, let’s start with a bit from the second paragraph:
This method ignores view objects that are hidden, that have disabled user interactions, or have an alpha level less than 0.01.
Let’s put some quick guard statements up front to handle these preconditions.
override func hitTest(_ point: CGPoint, with event: UIEvent?) -> UIView? {
guard isUserInteractionEnabled else { return nil }
guard !isHidden else { return nil }
guard alpha >= 0.01 else { return nil }
// ...
Easy enough. What’s next?
This method traverses the view hierarchy by calling the
-pointInside:withEvent:method of each subview to determine which subview should receive a touch event.
While a literal reading of the documentation makes it sound like -pointInside: is called on each of the subviews inside a for loop, this isn’t quite correct.
Thanks to a reader dropping breakpoints in -hitTest: and -pointInside:, we know -pointInside: is called on self (with the other guards), rather than on each of the subviews. So we can add this line of code to the other guards:
guard self.point(inside: point, with: event) else { return nil }
-pointInside: is another override point for UIView. Its default implementation checks if the point that is passed in is contained within the bounds of the view. If a view returns true for the -pointInside: call, that means the touch event was contained within its bounds.
With that minor discrepency out of the way, we can continue with the documentation:
If
-pointInside:withEvent:returns YES, then the subview’s hierarchy is similarly traversed until the frontmost view containing the specified point is found.
So, from this, we know we need to iterate over the view tree. This means looping over all the views, and calling -hitTest: on each of those to find the proper child. In this way, the method is recursive.
To iterate the view hierarchy, we’re going to need a loop. However, one of the more counterintuitive things about this method is we need to iterate the views in reverse. Views that are toward the end of the subviews array are higher in Z axis, and so they should be checked out first. (I wouldn’t quite have picked up on this point without this blog post.)
// ...
for subview in subviews.reversed() {
}
// ...
The point that we are passed is defined relative to the coordinate system of this view, not the subview that we’re interested in. Fortunately UIKit gives us a handy function to convert points from our reference to the reference frame of any other view.
// ...
for subview in subviews.reversed() {
let convertedPoint = subview.convert(point, from: self)
// ...
}
// ...
Once we have a converted point, we can simply ask each subview what view it thinks is at that point. Remember, if the point lies outside that view (i.e., -pointInside: returns false), the -hitTest will return nil, and we’ll check the next subview in the hierarchy.
// ...
let convertedPoint = subview.convert(point, from: self)
if let candidate = subview.hitTest(convertedPoint, with: event) {
return candidate
}
//...
Once we have our loop in place, the last thing we need to do is return self. If the view is tappable (which all of our guard statements assert), but none of our subviews want to take this touch, that means that the current view, self, is the correct target for the touch.
Here’s the whole algorithm:
override func hitTest(_ point: CGPoint, with event: UIEvent?) -> UIView? {
guard isUserInteractionEnabled else { return nil }
guard !isHidden else { return nil }
guard alpha >= 0.01 else { return nil }
guard self.point(inside: point, with: event) else { return nil }
for subview in subviews.reversed() {
let convertedPoint = subview.convert(point, from: self)
if let candidate = subview.hitTest(convertedPoint, with: event) {
return candidate
}
}
return self
}
Now that we have a reference implementation, we can begin to modify it to enable specific behaviors.
I’ve discussed one of those behaviors on this blog before, in Changing the size of a paging scroll view, I talked about the “old and busted” way to create this effect. Essentially, you’d
turn off
clipsToBounds.put an invisible view over the scrollable area.
override
-hitTest:on the invisible view to pass all touches through to the scrollview.
The -hitTest: method was the cornerstone of this technique. Because hit testing in UIKit is delegated to each view, each view gets to decide which view receives its touches. This enables you to override the default implementation (which does something expected and normal) and replace it with whatever you want, even returning a view that’s not a direct child of the original view. Pretty wild.
Let’s take a look at a different example. If you’ve played with this year’s version of Beacon, you might have noticed that the physics for the swipe-to-delete behavior on events feel a little different from the built-in stuff that the rest of the OS uses. This is because we couldn’t quite get the appearance we wanted with the system approach, and we had to reimplement the feature.
As you can imagine, rewriting the physics of swiping and bouncing is needlessly complicated, so we used a UIScrollView with pagingEnabled set to true to get as much of the mechanics of the bouncing for free. Using a technique similar to an older post on this blog, we set a custom page size by making our scroll view bounds smaller and moving the panGestureRecognizer to an overlay view on top of the event cell.
However, while the overlay correctly passes touch events through to the scroll view, there are other events that the overlay incorrectly intercepts. The cell contains buttons, like the “join event” button and the “delete event” button that need to be able to receive touches. There are a few custom implementations of the -hitTest: method that would work for this situation; one such implementation is to explicitly check the two button subviews:
override func hitTest(_ point: CGPoint, with event: UIEvent?) -> UIView? {
guard isUserInteractionEnabled else { return nil }
guard !isHidden else { return nil }
guard alpha >= 0.01 else { return nil }
guard self.point(inside: point, with: event) else { return nil }
if joinButton.point(inside: convert(point, to: joinButton), with: event) {
return joinButton
}
if isDeleteButtonOpen && deleteButton.point(inside: convert(point, to: deleteButton), with: event) {
return deleteButton
}
return super.hitTest(point, with: event)
}
This correctly forwards the right tap events to the right buttons without breaking the scrolling behavior that reveals the delete button. (You could try ignoring just the deletionOverlay, but then it won’t correctly forward scroll events.)
-hitTest: is an override point for views that is rarely used, but when needed, can provide behaviors that are hard to build using other tools. Knowing how to implement it yourself gives you the ability to replace it at will. You can use the technique to make tap targets bigger, remove certain subviews from touch handling without removing them from the visible hierarchy, or use one view as a sink for touches that will affect a different view. All things are possible!
