A side project I’m currently working needs an understanding of lots of different kinds of units. (I should probably be working on getting that off the ground instead of writing this blog post. Nevertheless.)
I’ve always found modeling units to be a fascinating programming problem. For time, for example, if you have an API that accepts a time, it’s probably going to accept seconds (or perhaps milliseconds! who can know!), but sometimes, you need to express a time like 2 hours. So instead of a magic number (7200, for the number of seconds in an hour), you write 2 * 60 * 60, perhaps adding spaces in between the operators to aid in “readability”.
7200, though, doesn’t mean anything. If you look at long enough and you have the freakish knack for manipulating mathematic symbols in your head, you might recognize it as two hours in seconds. If it weren’t a round number of hours, though, you never could.
And as that 7200 winds its way through the bowels of your application, it becomes less and less clear what units that mere integer is in.
A way to associate our integer with some metadata is what we need. Types have been described as units before, but can we bring that back to to units of measure, describing them with types? That can prevent us from adding 2 hours with 30 minutes and getting a meaningless result of 32.
(While it’s possible to handle this at the language level, most languages don’t have support for stuff like this.)
We still want to be able to add 2 hours to 30 minutes and get a meaningful result, so in our type system Time needs to be an entity, but Hours and Seconds do too.
Multiple things can be a Time, and each of those things must have a way to represented in seconds:
protocol Time {
var inSeconds: Double { get }
}
Each unit of time will each be its own thing, but it will also be a Time.
struct Hours: Time {
let value: Double
var inSeconds: Double {
return value * 3600
}
}
struct Minutes: Time {
let value: Double
var inSeconds: Double {
return value * 60
}
}
We could add similar structs for Seconds, Days, Weeks, et cetera, understanding that we’ll lose some precision as we go up in scale.
Now that we have a shared understanding of how our units of measure can be represented, we can manipulate that unit.
func + (lhs: Time, rhs: Time) -> Time {
return Seconds(value: lhs.inSeconds + rhs.inSeconds)
}
We can also add some handy conversions for ourselves:
extension Time {
var inMinutes: Double {
return inSeconds / 60
}
var inHours: Double {
return inMinutes / 60
}
}
And create a DSL-like extension onto Int, helpfully cribbed from ActiveSupport:
extension Int {
var hours: Time {
return Hours(value: Double(self))
}
var minutes: Time {
return Minutes(value: Double(self))
}
}
Which lets us write a short, simple, expressive line of code that leverages our type system.
let total = 2.hours + 30.minutes
(This result will of course be in Seconds so we will want some kind of presenter to reduce the units so that you can display this value in a meaningful way to the user. My side project has affordances for this. The side project is, unfortunately, in JavaScript, so no such type system fun will be had.)
I make a lot of hay about how to break view controllers up and how view controllers are basically evil, but today I’m going to approach the problem in a slightly different way. Instead of rejecting view controllers, what if we embraced them? We could make lots and lots of small view controllers, instead of lots of lots of small plain objects. After all, Apple gives us good ways to compose view controllers. What if we “leaned in” to view controllers? What benefits could we gain from such a setup?
I know a few people who do a subset of this. Any time there’s a meaningful collection of subviews, you can create a view controller out of those, and compose those view controllers together. This is a worthwhile technique, but today’s post will use a new type of view controller — one that defines a behavior — and show you how to compose them together.
Consider analytics. Often, I’ve seen analytics handled in a BaseViewController class:
@implementation BaseViewController: UIViewController
//...
- (void)viewDidAppear:(BOOL)animated {
[super viewDidAppear:animated];
[AnalyticsSingleton registerImpression:NSStringFromClass(self)];
}
//...
@end
You could have a lot of different behaviors in this base class. I’ve seen base view controllers with a few thousand lines of shared behavior and helpers. (I’ve seen it in Rails ActionControllers too.) But we won’t always need all this behavior, and sticking this code in every class breaks encapsulation, draws in tons of dependencies, and generally just grosses everyone out.
We have a general principle that we like to follow: prefer composition instead. Luckily, Apple gives us a great way to compose view controllers, and we’ll get access to the view lifecyle methods too, for free! Even if your view controller’s view is totally invisible, it’ll still get the appearance callbacks, like -viewDidAppear: and -viewWillDisappear.
To add analytics to your existing view controllers as a composed behavior rather than something in your superclass, first, set up the behavior as a view controller:
@implementation AnalyticsViewController
- (instancetype)initWithName:(NSString *)name {
self = [super init];
if (!self) return nil;
_name = name;
self.view.alpha = 0.0;
return self;
}
- (void)viewDidAppear:(BOOL)animated {
[super viewDidAppear:animated];
[AnalyticsSingleton registerImpression:self.name];
}
@end
Note that the alpha of this view controller’s view is set to 0. It won’t be rendered, but it will still exist. We now have a simple view controller that we can add as a child, we need a way to do so easily, to any view controller. Fortunately, for this, we can simply extend the UIViewController class:
@implementation UIViewController (Analytics)
- (void)configureAnalyticsWithName:(NSString *)name {
AnalyticsViewController *analytics = [[AnalyticsViewController alloc] initWithName:name];
[self addChildViewController:analytics];
[analytics didMoveToParentViewController:self];
[self.view addSubview:analytics.view];
}
@end
We can call -configureAnalyticsWithName: anywhere in our primary view controller, and we’ll instantly get our view tracking with one line of code. It’s encapsulated in a very straightforward way. It’s easily composed into any view controller, including view controllers that we don’t own! Since the method -configureAnalyticsWithName: is available on every single view controller, we can easily add behavior without actually being inside of the class in question. It’s a very powerful technique, and it’s been hiding under our noses this whole time.
Let’s look at another example: loading indicators. This is something that’s typically handled globally, with something like SVProgressHUD. Because this is a singleton, every view controller (every object!) has the ability to add and remove the single global loading indicator. The loading indicator doesn’t have any state (besides visible and not-visible), so it doesn’t know to disappear when the current view is dismissed and the context changes. Ideally, we’d like the ability to have a loading indicator whenever we need one, but not otherwise, and to be able to turn it on and off with minimal code. We can approach this problem in the same way as the analytics view controller.
@implementation LoadingViewController
- (void)loadView {
LoadingView *loadingView = [[LoadingView alloc] init];
loadingView.hidden = YES;
loadingView.label.text = @"Posting...";
self.view = loadingView;
}
- (LoadingView *)loadingView {
return (LoadingView *)self.view;
}
- (void)show {
self.loadingView.alpha = 1.0;
[self.loadingView startAnimating];
}
- (void)hide {
self.loadingView.alpha = 0.0;
[self.loadingView stopAnimating];
}
@end
And our extension to UIViewController a little more complex this time. Since we don’t have any configuration information, like the name in the analytics example, we can lazily add the loader the first time it needs to be used.
@implementation UIViewController (Loading)
- (LoadingViewController *)createAndAddLoader {
LoadingViewController *loading = [[LoadingViewController alloc] init];
[self addChildViewController:loading];
[loading didMoveToParentViewController:self];
[self.view addSubview:loading.view];
return loading;
}
- (LoadingViewController *)loader {
for (UIViewController *viewController in self.childViewControllers) {
if ([viewController isKindOfClass:[LoadingViewController class]]) {
return (LoadingViewController *)viewController;
}
}
return [self createAndAddLoader];
}
@end
Again, we see similar benefits. The loader is no longer a global; instead, each view controller adds its own loader as needed. The loader can be shown and hidden with [self.loader show] and [self.loader hide]. You also don’t have to explicitly add the behavior (a loader) in this example.
We get the benefit of simple invocations and well-factored code. Other solutions to this problem require you to use globals or subclass from one common view controller, whereas this does not.
This example doesn’t need access to the view lifecycle methods like the other ones. It only needs access to the view, which it gets just from being a child view controller. (If you wanted, you could also add more state, like a incrementing and decrementing counter for the number of in-flight network requests.)
Another example of a common view controller behavior that we would love to factor out is error presentation. As of iOS 8, UIAlertView is deprecated in favor of UIAlertController, which requires access to a view controller. In the Backchannel SDK, I use a class called BAKErrorPresenter that is initialized with a view controller for presenting the error. Instead, what if the error presenter was a view controller?
@implementation ErrorPresenterViewController
- (void)viewDidLoad {
[super viewDidLoad];
self.view.alpha = 0.0
}
- (void)viewDidAppear:(BOOL)animated {
[super viewDidAppear:animated];
self.isVisible = YES;
}
- (void)viewWillDisappear:(BOOL)animated {
[super viewWillDisappear:animated];
self.isVisible = NO;
}
- (UIAlertAction *)okayAction {
return [UIAlertAction actionWithTitle:@"OK" style:UIAlertActionStyleCancel handler:nil];
}
- (void)present:(NSError *)error {
if (!self.isVisible) { return; }
UIAlertController *alert = [UIAlertController alertControllerWithTitle:error.localizedDescription message:error.localizedFailureReason preferredStyle:UIAlertControllerStyleAlert];
[alert addAction:self.okayAction];
[self presentViewController:alert animated:YES completion:nil];
}
@end
Note that the error presenter can maintain any state it needs, such as isVisible from the lifecycle methods, and this state doesn’t gunk up the primary view controller.
I’ll leave out the UIViewController extension here, but it would function similarly to the loading indicator, lazily loading an error presenter when one is needed. With this code, all you need to present an error is:
[self.errorPresenter present:error];
How much simpler could it be? And we didn’t even have to sacrifice any programming principles.
For our last example, I want to look at a reusable component that’s highly dependent on the view appearance callbacks. Keyboard management is something that’s typically that needs to know when the view is on screen. Normally, if you break this out into it’s own object, you’ll have to manually invoke the appearance methods. Instead, you get that for free!
@implementation KeyboardManagerViewController
- (instancetype)initWithScrollView:(UIScrollView *)scrollView {
self = [super init];
if (!self) return nil;
_scrollView = scrollView;
self.alpha = 0.0
return self;
}
- (void)viewDidAppear:(BOOL)animated {
[super viewDidAppear:animated];
[[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(keyboardAppeared:) name:UIKeyboardDidShowNotification object:nil];
[[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(keyboardDisappeared:) name:UIKeyboardWillHideNotification object:nil];
}
- (void)viewWillDisappear:(BOOL)animated {
[super viewWillDisappear:animated];
[[NSNotificationCenter defaultCenter] removeObserver:self name:UIKeyboardDidShowNotification object:nil];
[[NSNotificationCenter defaultCenter] removeObserver:self name:UIKeyboardWillHideNotification object:nil];
}
- (void)keyboardAppeared:(NSNotification *)note {
CGRect keyboardRect = [[note.userInfo objectForKey:UIKeyboardFrameEndUserInfoKey] CGRectValue];
self.oldInsets = self.scrollView.contentInset;
UIEdgeInsets contentInsets = UIEdgeInsetsMake(self.oldInsets.top, 0.0f, CGRectGetHeight(keyboardRect), 0.0f);
self.scrollView.contentInset = contentInsets;
self.scrollView.scrollIndicatorInsets = contentInsets;
}
- (void)keyboardDisappeared:(NSNotification *)note {
self.scrollView.contentInset = self.oldInsets;
self.scrollView.scrollIndicatorInsets = self.oldInsets;
}
@end
This is a simple and almost trivial implementation of a keyboard manager. Yours might be more robust. The principle, however, is sound. Encode your behaviors into tiny, reusable view controllers, and add them to your primary view controller as needed.
Using this technique, you can avoid the use of global objects, tangled view controllers, long inheritance heirarchies, and other code smells. What else can you make? A view controller responsible purely for refreshing network data whenever the view appears? A view controller for validating the data in the form view? The possiblities are endless.
Last week, I tweeted that “reading lots of new blog posts in rss makes me way happier than reading lots of new tweets”.
Opening my RSS reading and finding 30 unread items makes me happy. Opening Twitter and seeing 150 new tweets feels like work. I’m not sure why that is. I think Twitter has become more negative, and the ease of posting quick bursts makes posting negative stuff easy. With blogging, writing something long requires time, words, and an argument. Even the passing thought of “should I post this” creates a filter that lets only better stuff through.
And I find myself running out of blog posts to read more quickly than tweets. Even though the content is longer-form, there are much fewer sources total. I want to fix this.
That same day on Twitter, I put out a call for new blogs. I got a few recommendations (all great!): Priceonomics from Allen Pike, The Morning News from Patrick Gibson, and Matt Bischoff’s tour-de-force of a tweet.
I’m looking for more, though, and blogs of a specific type:
Written by a single person with a voice and interests of their own
I like programming but I’m happy with other stuff too
Longer-form is better than shorter, but both are good
Prefer original content to link blogs
Ideally fewer than 2 or 3 posts per week
Send me tweets and emails about the awesome blogs you love, please! And don’t be afraid to promote your own blog. I want to read it. Over the last year, while looking at my referrers, I’ve found some awesome blogs that my readers have been quietly working on, such as Christian Tietze and Benedict Cohen. I’m not kidding, I want to see your blog.
Here are some blogs of the type that I’ve found myself enjoying the most recently.
Slate Star Codex might be my favorite blog I’ve found. Scott has a contrarian angle on isuses that’s not always right but is always interesting. If you email me, I’m happy to recommend my favorites of his posts.
Sometimes, it can be inspiring to read people in other programming communities writing good stuff, like Pat Shaughnessy and his blog. Zack Davis’s An Algorithmic Lucidity is great. There are blogs like Mike Caulfield’s and Manton Reece’s that read like a journal for a new project. It’s awesome to be along with them for the ride.
Blogs I’ve found beause of Swift stuff, like Olivier Halligon’s [Erica Sadun’s](Erica Sadun’s), Ben Cohen’s, and Russ Bishop’s. An amazing blog from a co-worker at Genius, James Somers. He never posts, but when he does, it’s worth the wait.
I think I miss blogrolls, too. One of those will probably make an appearance on this blog soon.
Over winter break last year, I went on vacation for two weeks. I had lots of time and not as much internet. With the downtime, I wrote three posts of ideas I’d been having. I figured I would post one a week in the new year.
I posted the first one, Finite States of America, when I got back. It got a little traction and so I wrote a follow-up, State Machinery. The next two weeks saw posts about The Coordinator and Categories in Objective-C. After a month of posting, I found I really liked having a once-a-week posting schedule. I decided to see how long I could keep going.
At the end of the year, WordPress sent me a year end statistics retrospecive, and it included a graph.
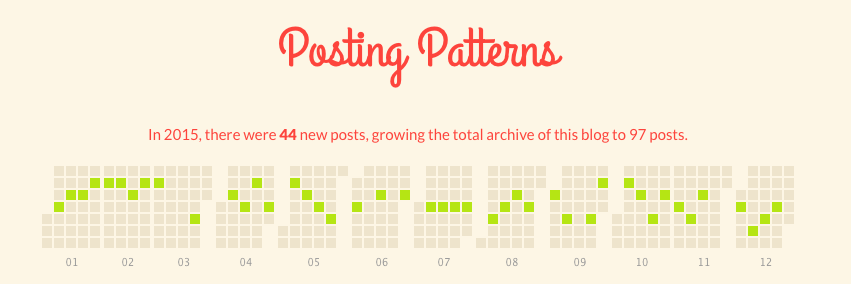
Each column is a week, and each green dot is a new post. This graph was coincidentally perfect for this project, because it clearly shows which weeks I post and which weeks i didn’t. (I missed three weeks in March for Ull and working on the Instant Cocoa release, two for WWDC, one for Thanksgiving, and one for NSSpain. I feel very guilty about missing those weeks and I’m sorry.)
Now, with the year over, I think I’m going to go a calmer posting schedule. Once a week, especially for the highly technical types of posts I write, is pretty extreme. I hope I can do twice a month. Time will tell.
Through the process, I learned a lot things.
The biggest thing I learned was that I could do this at all. In a roughly-mid-year retrospective, Throw It All Away, I wrote:
I’ve published 15 posts since January. It feels like a breakneck speed. If you asked me last year how long I could sustain such a pace, I think I would have answered, “maybe 4 weeks?”.
But I’m still going. And, somehow, even though back in December the list of potential topics had as many items on it as I’ve posted already, it’s still more or less the same length. I can’t explain it.
A lot of my friends asked me how I kept up such a crazy schedule. While it helped to have more people than usual reading my stuff and sending me positive feedback, the best thing was having a strict schedule and sticking to it. Making the blog a priority each week was the key. With 156 hours in each week, I of course had time to blog, it just needed to be prioritized over work, sleep, eating, social stuff, and binge watching the West Wing.
The second big thing I learned this year is that writing helps me figure out what I actually think. In this talk, Leslie Lamport quotes a cartoonist named Guindon in saying “Writing is nature’s way of letting you know how sloppy your thinking is.” I haven’t been able to source the quote any more specifically than that, but it’s a great quote.
When writing an argument down, it congeals into something more solid, and it’s so much easier to see the weak points and holes in the argument. For example, when I started writing A Structy Model Layer, my original intention was to show why structs didn’t make for good models. As I tried to flesh out my post and my thoughts, I realized that it was actually a more complicated issue than that, and sometimes structs are appropriate for model layers.
Writing so many posts helped me make clearer arguments and figure out what I really thought. I’m also glad that I have a repository of big, well-thought-out ideas that I can point people to. It was a great year, and since I’ve just started writing Swift for a client, more posts are just around the corner.
Over the course of the last year, I’ve blogged once a week. I’ve written about a broad range of ideas, but if there was one overriding concept, it was Massive View Controller. The idea of Massive View Controller all started from one simple tweet. It feels like the most obvious and pressing issue in terms of code quality in our industry.
Since my writing consists mostly of 1000-word chunks broken up by weeks, I wanted to assemble a compendium of different strategies I’ve written about.
8 Patterns to Help You Destroy Massive View Controller
The most important post I’ve written about the topic is 8 Patterns to Help You Destroy Massive View Controller. This contains lots of really practical advice for breaking up view controllers into composed units, like data sources, navigators, interactions, etc.
The thing that’s nice about writing code like this is not every view controller needs every one of these components. You just pick the ones you need and implement them. I also wrote about one of the patterns in its own blog post, called Smarter Views.
This post was written more than a year ago, so there’s lots of stuff I’d like to update in it, and patterns I would like to add and clarify.
Coordinators Redux
Coordinators Redux is a follow up post to The Coordinator from earlier this year. It’s a 3000-word treatise on why the view controller system is broken and how it leads to very messy entanglement between view controllers. The talk also comes in video form, which have some nice graphics breaking down what the benefits are here.
Coordinators make your view controllers simpler and more reusable. By taking the responsibility of flow management, it’s no longer necessary to have view controllers that know about each other. It also centralizes flow knowledge, instead of distributing it amongst many view controllers.
8 Patterns and Coordinators are my contributions to new ideas for the field. The other blog posts center around themes of how to think about this stuff.
Controllers are messed up
Mediating controllers, like Apple’s view controllers, which are sometimes known as adapters, have fundamental problems. In Model View Whatever, I examine the different overarching patterns that your app might use, such as model-view-controller (true MVC), model-view-adapter (which is more like what we call MVC today), model-view-viewmodel (MVVM), and a few others.
I went into further detail on MVVM last week in MVVM Is Not Very Good. The goal of this post isn’t to say that MVVM is bad. You’ll note the title explicitly says it’s just “not good”. Taking a huge chunk of code out of the view controller doesn’t help all that much if you just stick it all somewhere else. The goal of the post is to suggest that we could do way, way better.
In A Controller By Any Other Name, I analyze the harm caused by naming objects “Controller”. I wrote one of my favorite paragraphs ever in that post:
The harm caused by the “Controller” suffix is subtle, too. When you call something a Controller, it absolves you of the need to separate your concerns. Nothing is out of scope, since its purpose is to control things. Your code quickly devolves into a procedure, reaching deep into other objects to query their state and manipulate them from afar. Boundless, it begins absorbing responsibilities.
Lastly, in Emergence, I wrote about how the pain that we get from view controllers doesn’t happen by any malicious force. It happens purely by natural, emergent effects that happen as we’re working in the codebase “normally”.
Small Objects
The other big piece of keeping view controllers small is keeping all your objects small. If your view controller gets small, but some other view controller takes on the weight, that’s no solution at all. This is part of my complaint in the aforelinked “MVVM is not very good”.
I had a big revelation in Keeping Your Classes Shorter Than 250 Lines:
The critical epiphany for me was that if the same amount of code is spread among much smaller classes, there will have to be a lot more classes.
Examples of small objects, like those mentioned in 8 Patterns and the Cache object in Cache Me If You Can, help to break this stuff down.
In Anatomy of a Feature: Push Notifications, I take a look at what common feature, push notifications, looks like when broken down into many small objects. This same technique can be use with other subsystems of your app.
The two final techniques for making small objects that I’ve covered on this blog that I want to recap. The first is Pure Objects, which are an analog to functional programming’s pure functions. They don’t have access to any globals, don’t write to disk, don’t access the network. Their inputs completely define their outputs, and so they’re ripe for storing logic.
The other technique for making small projects that I’ve written about was in Graduation, which is step-by-step breakdown of the Method Object Pattern, a great way to turn your long nasty methods into beautiful simple objects.
These techniques won’t solve Massive View Controller on their own, but taken together, but they will take you a lot of way there. They also won’t do their work alone; as Smokey Bear once said, only you can prevent Massive View Controller.
I write a lot about making view controllers more digestable, and one very common pattern for doing that is called Model-View-ViewModel. I think MVVM is an anti-pattern that confuses rather than clarifies. View models are poorly-named and serve as only a stopgap in the road to better architecture. Our community would be better served moving on from the pattern.
MVVM is poorly-named
Names are important. Ideally, a name effectively messages what an object is for, what roles it fills, and how it’s used. “View model”, as a name, doesn’t do any of those things.
To make my case for me, the “view model”, on account how abstract it is, actually refers to two very different patterns.
The first type of “view model” is a “model for the view”. This is a dumb object (definitely a struct in Swift) that is passed to a view to populate its subviews. It shouldn’t contain any logic or even any methods. In the same way that a UILabel takes a string, or a UIImageView takes an image, your ProfileView can take a ProfileViewModel. It’s passed directly to your ProfileView, and it crucially allows you to make your subviews private, instead of exposing them to the outside world. This is a noble and worthwhile end. I’ve also seen this pattern called “view data”, which I like, because it removes itself from the baggage of the other definition of “view model”.
“View model” is also a name for a vague, abstract object that lies in between a model object and a view controller, which performs any data transformation necssary for presentation, as well as sometimes networking and database access, might do a little form validation and any other tasks you feel like throwing in there, and acts as a jack-of-all-trades object originally intended to transfer weight away from your controllers but ultimately creates a new kitchen sink for you to dump responsibilities into.
MVVM invites many responsibilities
The lack of concrete naming makes this class’s responsiblities grow endlessly. What functions should go in a view model? Nobody knows! Just do whatever.
Let’s look at some examples.
This post puts networking inside your view models, and recommends you add validations and presentation logic to it as well.
This post only shows how to put presentation logic in view models, raising the question of why it’s not called a Presenter instead.
This one says you should use them for uploading data and binding to ReactiveCocoa.
This one uses them for both form validation and fetching data.
This one takes the cake by specifically suggesting that you put “miscellaneous code” in a view model:
The view model is an excellent place to put validation logic for user input, presentation logic for the view, kick-offs of network requests, and other miscellaneous code.
Nobody has any idea what the words “view model” mean, and so they can’t agree on what to put in them. The concept itself is too abstract. None of these writers would disagree about what goes in a Validator class, or a Presenter class, or a Fetcher class, and so on. Those are all better names with tightly defined roles.
Giving the same name to a wide variety of different objects with drastically different responsibilities only serves to confuse readers. If we can’t agree view models should do, what’s the benefit to giving them all the same name?
Our discipline has already faced a similar challenge, and we found that “controller” was too broad of a name to be able to contain a small set of responsbilities.
You’re totally free to give your classes whatever names you want! Pick good ones.
MVVM doesn’t change your structure
Finally, view models don’t fundamentally alter how you structure your app. What’s the difference between these two images? (source)


You don’t need an advanced graph theory class to see that these are almost completely identical.
The most charitable thing that I can say about this pattern is that it changes your kitchen sink from a view controller, which is not an object that you own (because it’s a subclass of an Apple class), to a view model, an object that you do own. The view controller is now free to focus on view-lifecycle events, and is simpler for it. Still, though, we have a kitchen sink. It’s just been moved.
Because the view model is just one, poorly-defined layer added to your app, we haven’t solved the complexity problem. If you create a view model to prevent your view controller from getting too big, then what happens when your app’s code doubles in size again? Maybe at that point we can add a controller-model.
The view model solution doesn’t scale. It’s a band-aid over a problem that will continue to come up. We need a better solution, like a heuristic that allows you to continually divide objects as they get too big, like cells undergoing mitosis. View models are just a one-time patch.
Other communities have already been through this
The Rails community has gone through this problem some years ago, and they’ve come out on the other side. We could stand to learn from their story. First, they had fat controllers, and almost nothing but persistence in their models. They saw how untestable this was, and so they moved all the logic down into the model, and ended up with a skinny controller, and a fat model. The fat model, since it was reliant on ActiveRecord, and thus the database, was still too hard to test and needed to be broken down into many smaller components.
Blog posts like 7 Patterns to Refactor Fat ActiveRecord Models (which was the inspiration for my own 8 Patterns to Help You Destroy Massive View Controller) are an example of the product of this chain of thought. Eventually, you’re going to have to separate your concerns into small units, and moving your kitchen sink is only going to delay the reckoning.
View models are a solution that is totally unsuited to the challenges of modern programming. They are poorly-named constructs that don’t have a sense of what they should contain, which causes them to suffer the same problems as view controllers. They are only a temporary patch to a complicated problem, and if we don’t avoid them, we’ll have to deal with this problem again in the near future.
This week, I’d like to examine building your entire model layer out of Swift structs. Swift allows you to build your objects in two ways: values types and references types.
Reference types behave more like the objects we’re used to. They’re created with the class keyword, and they are pass-by-reference. This means that multiple other pieces of code could have a handle on the same object, which, when combined with mutable properties, can lead to issues of thread safety and data in an inconsistent state.
Value types, on the other hand, are pass-by-value. They’re created with the struct keyword. Passing things by value means that, in practice, two pieces of code can’t mutate the same struct at the same time. They’re commonly used for types that are mostly a bag-of-data.
In Objective-C, you didn’t have the ability to use value types at all. In Swift, we have a new thing called a struct which automatically copies itself every time it’s used in a new place. At first blush, this seems like exactly what we want for our model layer. It holds data and can’t be shared between threads, making it much safer. I want to know, can I write my whole model layer out of this?
Drew Crawford wrote a post called “Should I use a Swift struct or a class?”. The general idea is that with the advent of this new tool (structs), a lot of people have promoted writing as much of your code as possible in structs, rather than classes.
This leads to vaguely positive statements like Andy Matuschak’s in which he is “emphatically not suggesting that we build everything out of inert values” and yet we should “Think of objects as a thin, imperative layer” which presumably leaves a thick layer of values for everything else, and “As you make more code inert, your system will become easier to test and change over time” which is vaguely true but when taken to its logical conclusion seems to contradict his earlier statement that “not everything” should be a struct.
Drew’s general recommendation is that when it’s meaningful for the type to conform to Equatable, it can be a struct. If not, it should be a class. This suggests that our model objects maybe should be represented as a struct. My model objects usually do conform to Equatable, comparing the values that represent their identity.
Drew also quotes Apple’s book on Swift:
As a general guideline, consider creating a structure when one or more of these conditions apply:
The structure’s primary purpose is to encapsulate a few relatively simple data values.
This, on the other hand, suggests that structs are too simplistic for the model layer. Models are usually more than “a few relatively simple data values”.
Examples of good candidates for structures include:
The size of a geometric shape, perhaps encapsulating a width property and a height property, both of type Double.
A way to refer to ranges within a series, perhaps encapsulating a start property and a length property, both of type Int.
A point in a 3D coordinate system, perhaps encapsulating x, y and z properties, each of type Double.
These sound like parts of a model, rather than model layer itself.
Because model objects lie in a gray area between “things that need to be alive and responsive” and “things whose central job is to hold data”, I’m surprised to see models-as-structs question hasn’t been asked yet.
Models are primarily value data (like strings and integers) and there are going to be people who try to make their whole model layer out of structs, so I think it’s worth it to examining this approach. After all, the “models” in a purely functional programming language like Haskell has to be pass-by-value. Can’t it be done here?
The answer is, in short, yes. But there are a lot of caveats.
Persistence is much more difficult. You can’t conform to NSCoding without being an NSObject. To use NSCoding with a struct, you have to outsource your object encoding to a reference type, as I lay out in this post. Core Data and Realm are totally not options, since those both have to subclass from NSManagedObject and Realm’s Object. To use them, you have to define your model twice and painstakingly copy properties from your structs to your persistence objects.
Changes in one model struct won’t be reflected elsewhere. In a lot of cases, changing a property of a object should be reflected in more than one place. For example, faving a tweet in a detail view should be reflected on the timeline as well. If you need behavior like that, be prepared to write a bunch of state maintenence code and notifications for shuttling those changes around to every corner of your app that needs them.
You can’t have circular references. Some people might consider this a pro rather than a con, but structs can’t describe circular relationships. If you want to get all the tags of a post, and then go find all the posts of one of those tags, you’re going to have to either duplicate the data or go through intermediate objects. Your data must be a hierarchal/tree structure, and can’t contain loops. This is what JSON looks like by default, so if your app’s model is a thin layer over a web service, this is less of a downside for you.
Not all types in your model will be representable by value types. Specifically, colors, URLs, data, fonts, and images, even though they act like values, can only be represented by class-based reference types, like UIColor, NSURL, and their companions. To make these truly value types, you’ll have to do work either wrapping that class in a struct, or defining a new data structure that represents the data and can be readily converted into a Foundation- and UIKit-friendly type.
If you want to make your model layer out of structs, it’s not impossible, but the downsides can be great. As with the rest of programming, it’s a trade-off that you must weigh to make a decision.
Last year, I wrote 8 Patterns to Help You Destroy Massive View Controller. It contains lots of boots-on-the-ground advice for how to break up a view controller. One of the patterns I brought up in that post was the Smarter View, which I want to explore here.
To create a Smarter View, you move the view-y responsibilities out of the view controller and into the view itself. This includes allocation and configuration of subviews, as well as any view-related logic into a subclass of UIView. As an example, let’s take a look at the message form from the Backchannel SDK. (It’s so nice to be able to refer to complete code examples, instead of tiny snippets littered all over the blog!)
Before, the logic for allocating subviews might be in lazy loaders on the view controller, in the view controller’s -loadView, or in the view controller’s -viewDidLoad. View layout might be in -viewDidLayoutSubviews, or scattered across the class. By moving all that stuff down a view subclass, we free up the view controller.
To make a Smarter View, we redeclare the view property:
@property (nonatomic) BAKMessageFormView *view;
Mark it as @dynamic :
@dynamic view;
And all we’re left with inside the view controller is a short -loadView method:
- (void)loadView {
self.view = [[BAKMessageFormView alloc] init];
}
Once that’s done, I usually add an extra read-only property for getting the view itself. Inside the view controller, when calling specific methods that are only on BAKMessageFormView, I use this property:
- (BAKMessageFormView *)messageForm {
return self.view;
}
The reason for this is a little subtle. If the structure of this view controller ever changes, and self.view isn’t a BAKMessageFormView anymore, I don’t want every message that I sent to self.view to be an error that needs fixing. I’ll just change this read-only property to point to the new place where other code can find the messageForm, and all the references that point to it will go to the right place. Probably, this structure will never change (and practically, it wouldn’t be that much effort to change all the references), but I like to separate when I’m talking to the view as a UIView and when I’m talking to the view as a BAKMessageFormView.
Views also encapulate layout. In most cases, I found it simpler to push layout down even further, into its own object. The layout for Backchannel’s message form is a great example. (This would be a struct in Swift.) It’s called in the view’s -layoutSubviews :
- (void)layoutSubviews {
[super layoutSubviews];
BAKMessageFormLayout *layout = [[BAKMessageFormLayout alloc]
initWithWorkingRect:self.bounds
layoutInsets:self.layoutInsets
originalTextContainerInset:self.originalTextContainerInset
shouldShowAttachmentsField:self.shouldShowAttachmentsField
shouldShowChannelPicker:self.shouldShowChannelPicker];
self.loadingView.frame = layout.loadingRect;
self.bodyField.frame = layout.bodyRect;
self.bodyField.textContainerInset = layout.bodyInset;
self.subjectFormField.frame = layout.subjectRect;
self.attachmentsFormField.frame = layout.attachmentsRect;
self.channelPickerFormField.frame = layout.channelsRect;
self.paperclipButton.hidden = self.shouldShowAttachmentsField;
}
The benefit to moving this stuff down is that, via the method-object pattern, local variables in the method become instance variable in the object, so you can separate all the constants for a given layout out, and end up with cleaner code.
//...
- (CGFloat)leftMargin {
return 15;
}
- (CGFloat)leftTextInset {
return 10;
}
- (CGFloat)subjectHeight {
return 44;
}
//...
In addition to view allocation and layout, the view can also encapsulate litte bits of logic. For example, when posting a reply in an already existing thread, the subject field should be filled in and disabled.
- (void)setSubjectFieldAsDisabledWithText:(NSString *)text {
self.subjectField.text = text;
self.subjectField.enabled = NO;
}
Because the view is now aware of what kind of subviews it’s going to have, it’s easy to add logic around those subviews.
If you’ll notice, UITableViewController has a smarter view. It has a UITableView view property, and that contains all the logic for layout and cells reuse.
Back when I wrote the 8 Patterns post, I hadn’t actually implemented Smarter View anywhere. A year later, and almost every view controller I write has a custom view subclass. It’s a technique I can’t recommend more highly.
Backchannel is streamlined way for app developers to gather feedback from beta testers, right within their apps. Backchannel lets both developers and their beta testers comment on and discuss feature requests, bug reports, and general feedback about the app._
Last week, I wrote about how the classes of the Backchannel SDK are all under 250 lines of code. This week, I’d like to discuss the experience of writing a significant application with zero dependencies.
Not having any dependencies makes it a lot easier for developers (your customers!) to incorporate your code into their project. You’re assured that your dependencies won’t clash with their dependencies, no extraneous weight will be added to your customer’s projects, and that your dependencies won’t add any categories or swizzling to your customer’s projects.
When I started out writing Backchannel’s SDK, I had just come off the heels of releasing Instant Cocoa, which is a library I created for reducing the intense amount of boilerplate we have to deal with as iOS developers. It includes abstractions like data sources, which map index paths to objects, or resource gateways, which provide a clean interface for touching REST APIs through model objects.
I wanted to use all of this code that I had meticulously spent a year and half writing and perfecting and genericizing. However, I knew I couldn’t include it. It wouldn’t have been fair of me to expect other developers to import an enormous library of mine into their app just so that my development experience could be nicer.
So I turned this limitation into a feature. Not only would Backchannel not have my library, but it wouldn’t have any dependencies at all. It would be a bit more work, but the developers using it would appreciate it, and that would make it worthwhile.
I had to rewrite a few of the Instant Cocoa features, like data sources. Data sources in Instant Cocoa are a lot more generic, allowing you to mix, match, and combine them in interesting ways. Since Backchannel doesn’t need any of that, it was all reduced to one simple data source, that allows for a list to be downloaded from an API, mapped to local domain objects, and presented to a table view.
Preventing Instant Cocoa from being in the project meant that the code was more tightly focused and easier to understand. BAKCache or BAKSendableRequest are two other examples of classes with interfaces that were limited to exactly what I wanted them to be.
Writing an application with zero dependencies means you have to take responsibility for every line of code in your app. You can’t offload networking, persistence, object mapping, or any other component to someone else’s code. It’s just you, UIKit, and Foundation.
Backchannel was going to need Keychain access (to store the user’s API access token). I didn’t know much about how the Keychain API worked. I’d only heard that its API was bad, and to use something like Apple’s GenericKeychain to wrap it.
I set off looking for GenericKeychain, so that I could copy it into my project. When I found out, I realized that there’s no way I could take responsibilty for that code. GenericKeychain is a mess, barely better than the C API it wrapped. (In a future blog post, I’m hoping to go into GenericKeychain as a case study of how not to write classes.) I spent about a day understanding how Apple’s code worked, and wrote my own wrapper around the Keychain API, with exactly the API I wanted and the features I needed, and thus BAKKeychain was born.
The networking API was another example of code I had to design myself. Other networking libraries couldn’t be relied upon. For example, AFNetworking puts a category onto UIImageView, which could conflict with code that the developer has already written.
I turned the experience of creating a networking layer into a blog post series, analyzing what was wrong with the currently available strategies, how I structured my version, a follow up on advanced techniques like pagination and mulitipart requests, and a follow up with a Swift version of the same ideas. Writing my own networking code cost some development time, but I can now stand behind the code, because I wrote it and understand it fully.
A few weeks ago, Ben Sandofsky wrote about minimizing usage of libraries. He argues for being very circumspect about which libraries you decide to import. I agree with all of his points, but I will go a step further and say that it’s even more instructive to limit yourself to zero dependencies. What kind of abstractions will you make when you aren’t bound by the ways others have solved the same problems?
I found that I solved the problems in new and interesting ways, and many of those lessons are applicable in other apps as well. I’ll almost definitely be bringing the new networking concepts to Instant Cocoa and removing its dependency on AFNetworking.
Making a hard rule like “no dependencies” is a great way to test the limits of your code writing ability and forces you to get creative and make some awesome stuff.
I’ve heard that John Carmack begins every new game he works on by writing the simple functions he needs and building everything up from little pieces. He doesn’t even copy and paste his implementations from previous versions, preferring to write them from scratch. I’ve always been dismissive of that idea, but who knows? Maybe I’m coming around.
Backchannel is out, and so is its SDK. I wanted Backchannel’s code to be as polished as possible, to help build trust with other developers. Having no categories, no dependencies, and no weird tricks like swizzling is essential for building that trust, but, ultimately, the code needs to be easily readable.
One way that Backchannel’s SDK maintains its readability is through simplicity. No class in Backchannel is longer than 250 lines of code. When I was newer at programming, I thought that Objective-C’s nature made it hard to write short classes, but as I’ve gotten more experience, I’ve found that the problem was me, rather than the language. True, UIKit doesn’t do you any favors when it comes to creating simplicity, and that’s why you have to enforce it yourself.
Ben Orenstein, in his Simple Rules for New Programmers, says
Just as your classes should contain tiny methods, so should your system be built of tiny classes.
The critical epiphany for me was that if the same amount of code is spread among much smaller classes, there will have to be a lot more classes.
So, how does Backchannel maintain its small class sizes? A lot of classes. If I could come up with a name for it, I made it into a new class. If it was reused code, I figured out a name for it and made it into a new class. Since the code is open-source, I want to touch on some specific techniques here.
Backchannel’s SDK is essentially a whole app that lives inside your app, so the techniques here are as applicable for a regular app as they are for an SDK.
First, and most important, I stuck to a consistent pattern of code. In a normal app, your app delegate creates a UIWindow and sets up your root view controller. From there, each view controller pushes on more view controllers as needed. Instead, in the Backchannel SDK, I used Coordinators to manage the high-level flow of each task, and pushed extraneous code I could down to children of the view controller. This helped take as much stuff as possible out of the view controller. Taking authentication as an example, this involved using:
Coordinators to handle app flow and data manipulation (BAKAuthenticationCoordinator.m)
Requests to the API as separate classes (BAKCreateAccountRequest.m, BAKSignInRequest.m)
View controllers that handled data presentation and corralling user input (BAKAuthenticationViewController.m)
Views that handled allocating subviews and managing their layout (BAKAuthenticationForm.m)
Layout objects for calculating the layouts (BAKAuthenticationFormLayout.m)
By breaking each of these things down further and further, when a new change came in, it was obvious where to add the code to start working on that feature. Good naming also enables other developers to take a look at the file names and guess where they might want to start editing.
Line length isn’t a perfect metric for complexity (there are others), but it makes a great first approximation, since it’s so easy to determine. One of the most complicated classes in the Backchannel SDK is the message creation coordinator, with three different initializers and the task of coordinating between many small pieces. It’s no coincidence that it’s also one of the longest files. It’s also a ripe target for refactoring and breaking up.
Managing complexity by adding classes is the key here. The second technique I want to touch on is using different classes for similar concepts that are used in different ways. For example, the Backchannel SDK includes both BAKDraft and BAKMessage .
Even though they both have many similar properties, like a text body and an array of attachments, they serve different purposes: BAKDraft is used as a data clump for the data that the BAKMessageFormViewController generates, and BAKMessage is the message’s representation after it’s created in the API and includes information about display metrics and user permissions. BAKMessage has room to grow to handle new things from the API, whereas BAKDraft might expand into a persistent format for saving drafts that the user is working on.
These two objects are nominally the same thing, and it might have been possible to use BAKMessage in the place of BAKDraft. Nevertheless, the two concepts fill different roles, have different capabilities and benefit from being separate. Shoehorning them into the same class would be ugly, inelegant, and restrictive.
Finally, there are concepts that you know will need to be encapsulated and separated into their own space, but don’t lend themselves easily to a name. Without a good name, it’s hard to tell what should be in the class and what shouldn’t. In those cases, I find that the best way to develop the identity for the class is not through its name, but rather through its members.
For example, in Backchannel, images upload in the background while the user types out the rest of their message. If the user taps the “Post” button while images are still uploading, posting is delayed until all of the images have uploaded. This definitely sounds like a bit of state I want to encapsulate, potentially with a dispatch_group_t. I built an object around this dispatch group, and it eventually became BAKAttachmentUploader.
I think that name is ultimately pretty weak (a rough rule for me is if the class name ends in -er, it’s not the best name). The class’s name doesn’t really reveal what its interface should be. However, I knew that my class would have a method like - (void)waitForAttachmentUploads:((^)())block and it identity would revolve around the dispatch group, and so a new object was born.
There’s lots of little objects (they might even be enums or structs in Swift) in the Backchannel SDK that perform little tasks into which I won’t go into depth here. (Some interesting ones to explore are BAKMessageCreator , BAKAuthenticationData , or BAKErrorPresenter .) While practicing the technique of making more little objects than you’re used to, it might be worthwhile to play a game with yourself to find out what the smallest interesting object you can make is. If it encapsulates a useful piece of logic or data, you might find that you like having it around.
To find the 20 .m files with the longest length, you can use the following bash command from inside your iOS project repo:
find . -name "*.m" -type f -print0 | xargs -0 wc -l | sort -rn | head -n 20
Pick one of those files and refactor it until it’s not in the list top 20 anymore. Continue until you’re happy.
